What Is Blosc?
Blosc2 is a high-performance compressor and data format optimized for binary data. As the successor to the original Blosc library, it is designed for speed by leveraging multi-threading and SIMD instructions (SSE2, AVX2, AVX512, NEON, ALTIVEC). It uses a blocking technique to divide datasets into blocks that fit in CPU caches, dramatically reducing memory bus activity and breaking down memory walls.
With a large diversity of codecs and filters, Blosc2 allows developers to fine-tune the balance between compression speed and ratio. It is a mature, open-source project with over 60 contributors and 3500+ commits, and is integrated into many popular scientific computing libraries, such as PyTables, h5py (via hdf5plugin), and Zarr.
Watch this introductory video to learn more about the main features of Blosc:
Key Features
Blosc2 offers several advantages that make it a compelling choice for high-performance applications:
Optimized for Binary Data: Uses shuffle and bit-shuffle filters (among others) that leverage data type information to improve compression ratios. It also has minimal overhead (max 32 bytes per chunk) on non-compressible data.
Multi-platform: Supports a wide range of platforms, including Linux, macOS, Windows, and WebAssembly (WASM). It is written in C, with bindings available for Python.
Multi-Dimensional Data (NDim): Provides native support for n-dimensional datasets through its NDim container. This container uses an innovative partitioning scheme that enables highly efficient slicing operations, even on sparse datasets.
Large Containers: Supports data sizes up to 2^59 bytes (1/2 exabytes) through its super-chunk implementation, overcoming the 2 GB limitation of Blosc1.
Persistent Storage: Includes Frames, a container format for serializing data in-memory or on-disk.
Advanced Computing with Python: The Python-Blosc2 package is more than a wrapper. It provides a powerful computing engine for performing lazy evaluations on compressed data, including reductions, broadcasting and support for many NumPy functions, avoiding the need to decompress data before processing. This is particularly useful for large datasets, as it allows you to work with data that doesn't fit in memory.
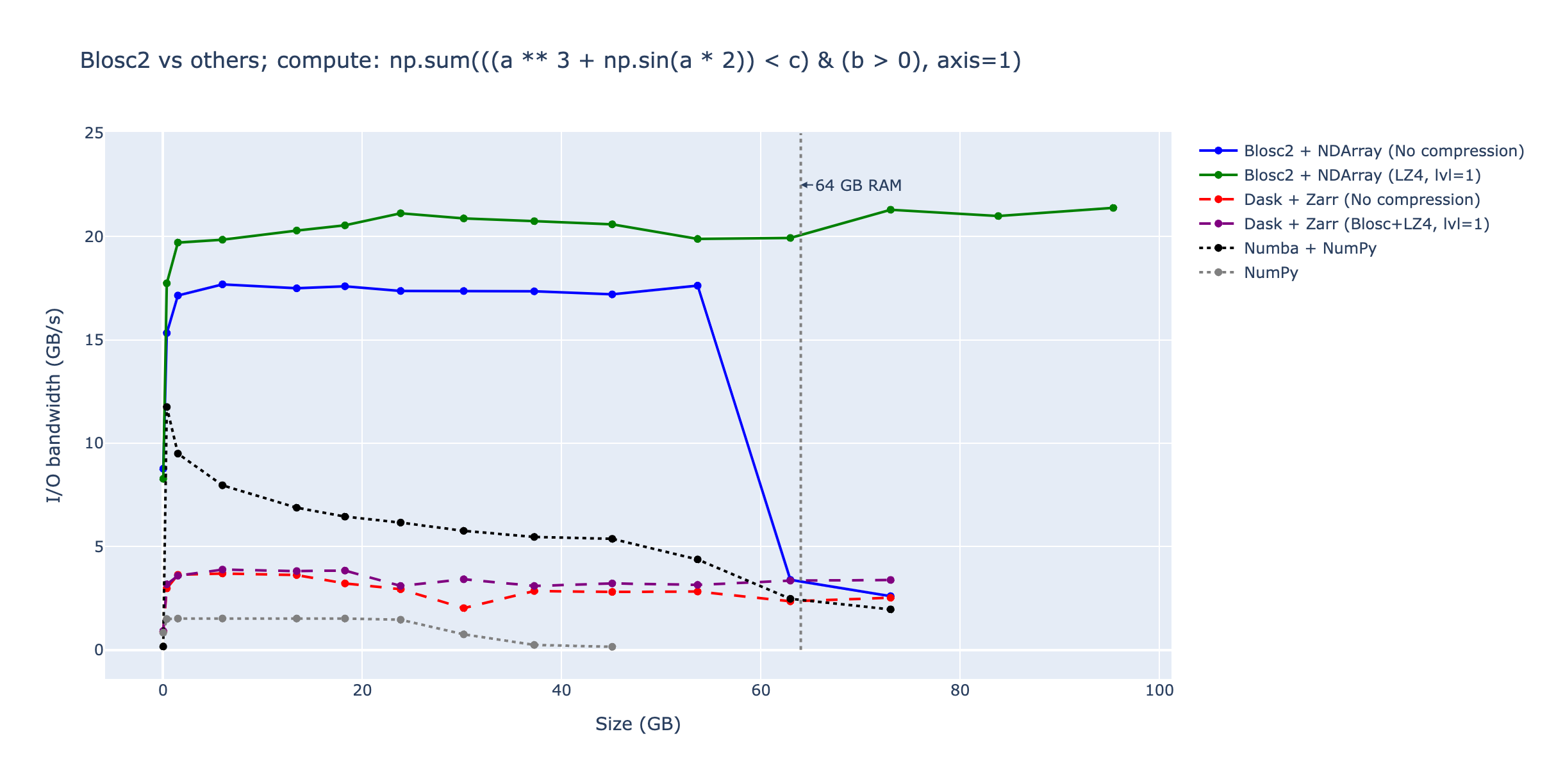
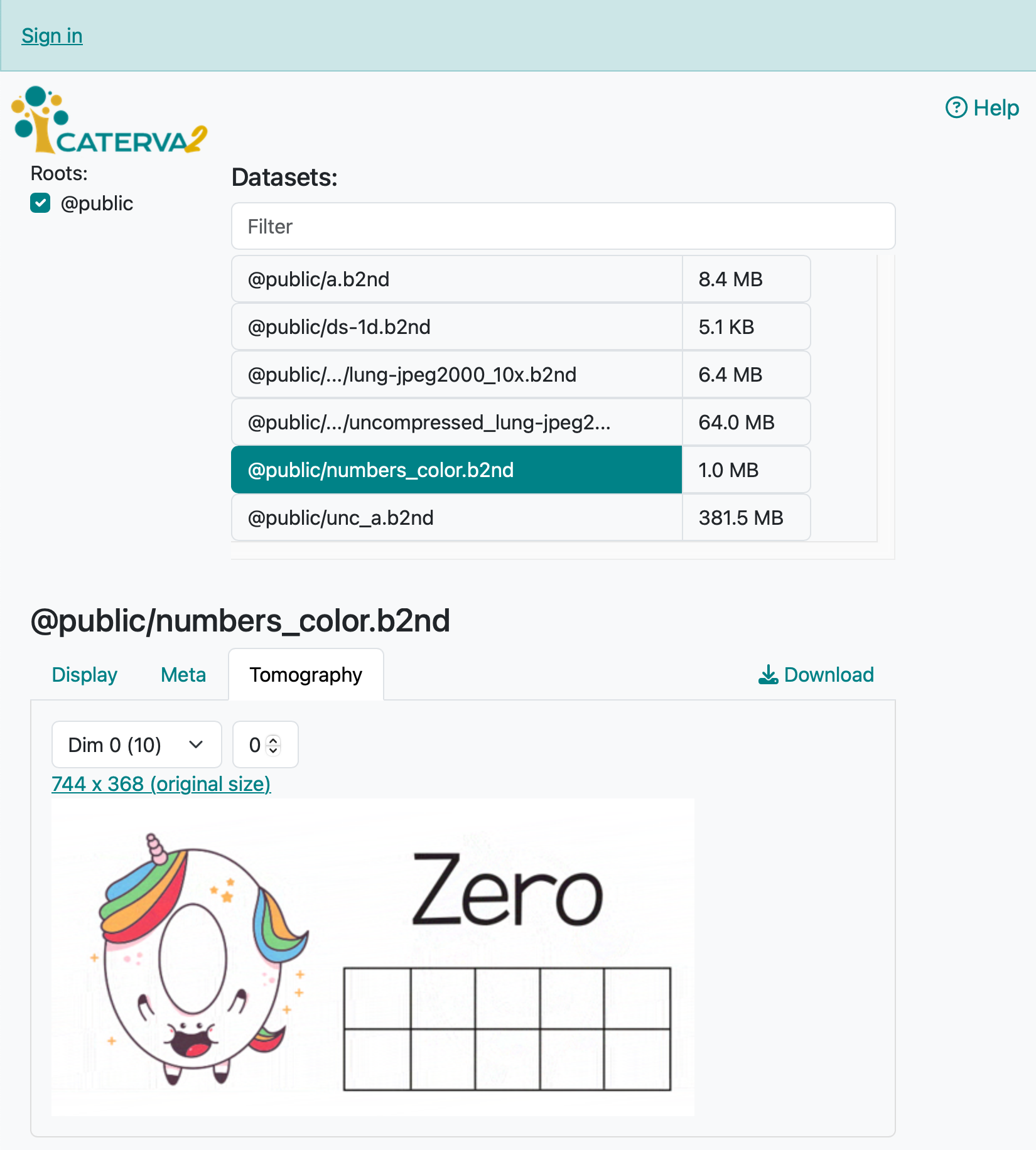
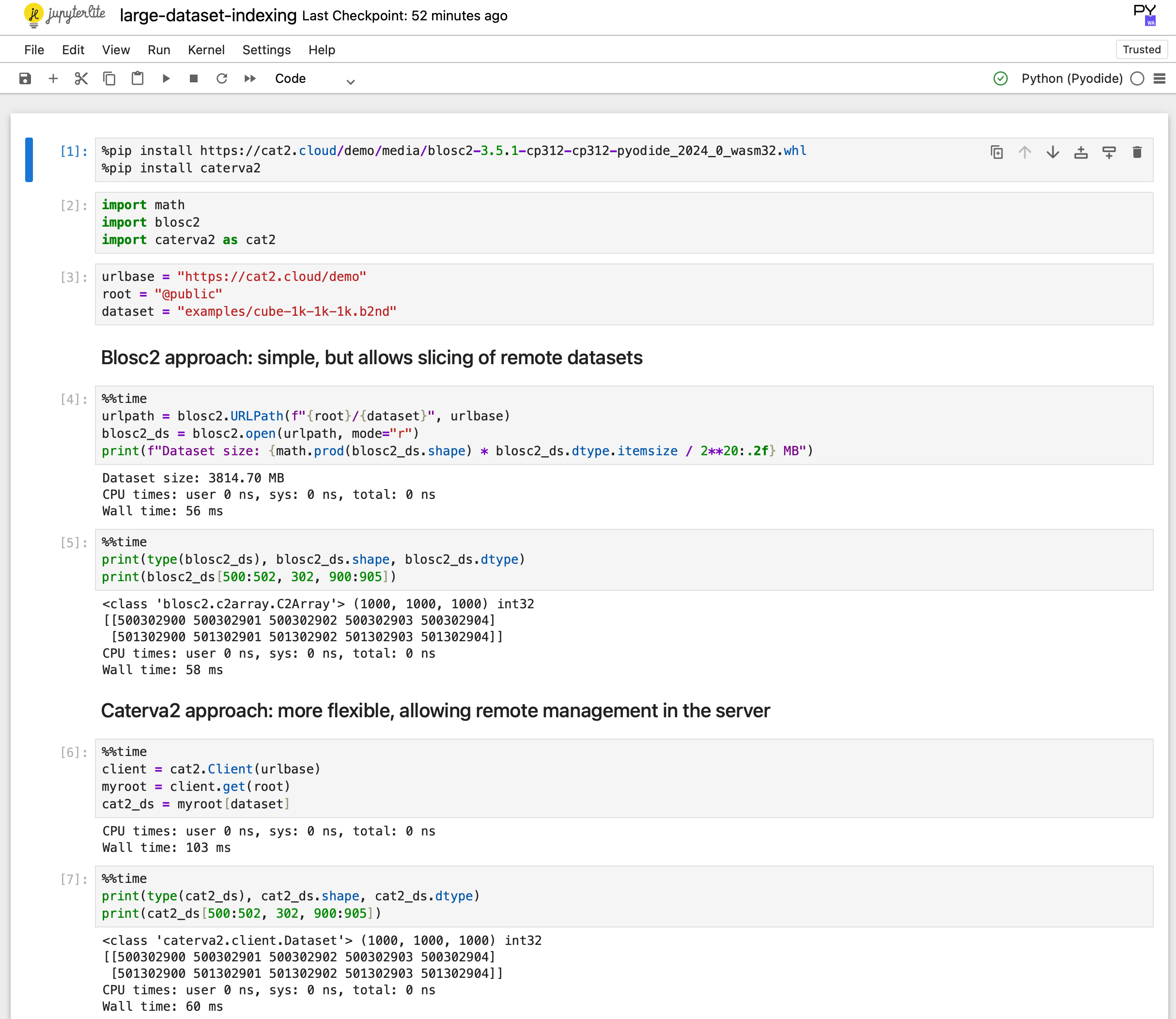
Access Data in the Cloud: Blosc2 supports accessing data stored in the cloud either directly, via the Caterva2 library, or through Cat2Cloud, a cloud-native service that enables working with large datasets efficiently without downloading them to your local machine.
|
|
For a complete list of features, please refer to our ROADMAP and recent progress reports.
Open and Extensible
Blosc2 is an open and fully documented format, ensuring you are not locked into a proprietary solution. The specification is concise and easy to implement.
We understand that every use case is unique. You can register your own codecs and filters to adapt Blosc2 to your specific needs. Furthermore, Btune, a machine learning tool, can automatically find the optimal compression parameters for your data.
Get Involved
The home for all Blosc-related libraries is on GitHub. You can download the source code, file tickets, and contribute to the project there.
GitHub: https://github.com/Blosc
C-Blosc2 Documentation: https://www.blosc.org/c-blosc2/c-blosc2.html
Python-Blosc2 Documentation: https://www.blosc.org/python-blosc2/python-blosc2.html
Stay informed about the latest developments by following us on our social networks:
LinkedIn: https://www.linkedin.com/company/blosc
Mastodon: https://fosstodon.org/@Blosc2
BlueSky: https://bsky.app/@blosc.org
Mailing List: http://groups.google.com/group/blosc
Support Blosc for a Sustainable Future
Blosc is the result of countless hours of effort by dedicated developers and the generous backing of organizations like NumFOCUS and ironArray SLU. Financial contributions are critical for the long-term sustainability of open-source projects like Blosc.
Your support helps us continue development, maintenance, and innovation. Here are some ways you can contribute financially:
NumFOCUS: Blosc is a fiscally sponsored project of NumFOCUS, a nonprofit supporting open-source scientific computing.
ironArray: ironArray SLU drives Blosc2 development and offers commercial support and consulting services.
GitHub Sponsorship: You can support us directly by clicking the "Sponsor" button on GitHub.
Thank you for helping us build a sustainable future for the Blosc ecosystem!
-- The Blosc Development Team