User-defined codecs and filters¶
While Python-Blosc2 offers many standard codecs and filters to enable custom compression, one may wish to use user-defined compression algorithms. This is possible in Python-Blosc2 via Python functions which may act as user-defined codecs and filters. These will work as normal codecs or filters respectively following the order depicted below:
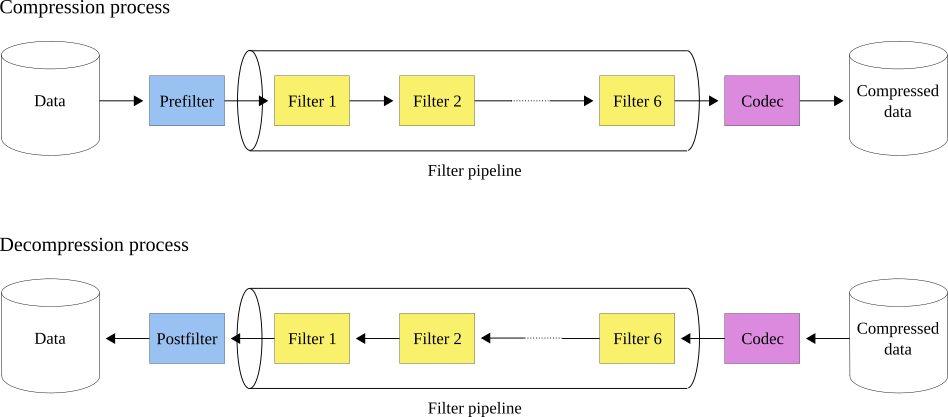
So when compressing, the first step will be to apply the prefilter (if any), then the filter pipeline with a maximum of six filters and, last but not least, the codec. For decompressing, the order will be the other way around: first the codec, then the filter pipeline and finally the postfilter (if any).
In this tutorial we will see how to create and use custom codecs and filters (see the next tutorial for post-/prefilters).
User-defined codecs¶
Predefined codecs in Blosc2 use low-level C functions and so are amenable to parallelisation. Because a user-defined codec has Python code, we will not be able to use parallelism, so nthreads has to be 1 when compressing and decompressing. We set nthreads=1 in the CParams and DParams objects that we will use to create the SChunk instance. When using user-defined codes, we may also specify codec_meta in the CParams instance as an integer between 0 and 255 (see
compcode_meta here). This meta will be passed to the codec’s encoder and decoder functions, where it can be interpreted as one desires. We may also pass filters_meta in the CParams object, which will be passed to the user-defined filters forward and backward functions. Later on, we will update the CParams object with our user-defined codec and filters, and update the meta at the same time.
[1]:
import sys
import numpy as np
import blosc2
dtype = np.dtype(np.int32)
cparams = blosc2.CParams(nthreads=1, typesize=dtype.itemsize)
dparams = blosc2.DParams(nthreads=1)
chunk_len = 1000
schunk = blosc2.SChunk(chunksize=chunk_len * dtype.itemsize, cparams=cparams, dparams=dparams)
Creating a codec¶
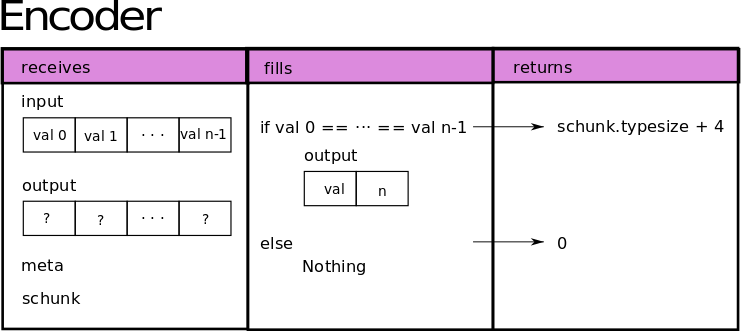
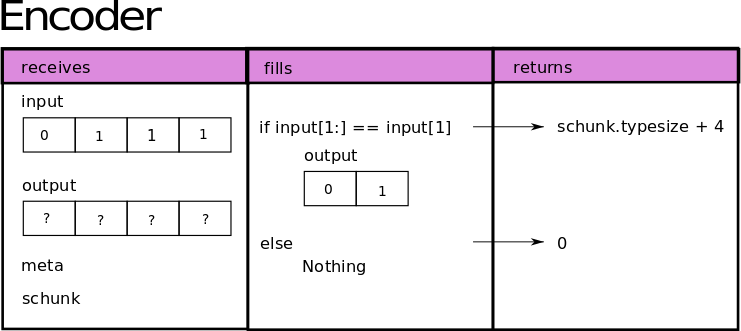
To create a codec we need two functions: one for compressing (aka encoder) and another for decompressing (aka decoder). In order to explain the procedure, we will create a codec for repeated values. First we programme the encoder function:
[2]:
def encoder(input, output, meta, schunk):
nd_input = input.view(dtype)
# Check if all the values are the same
if np.max(nd_input) == np.min(nd_input):
# output = [value, nrep]
output[0 : schunk.typesize] = input[0 : schunk.typesize]
byteorder = "little" if meta == 0 else "big"
n = nd_input.size.to_bytes(4, byteorder)
output[schunk.typesize : schunk.typesize + 4] = [n[i] for i in range(4)]
return schunk.typesize + 4
else:
# memcpy
return 0
In order to be compatible with the Blosc2 internal compression machinery, which operates blockwise, the encoder function requires 4 arguments: the input data block; the output buffer into which the data is compressed; the codec meta (which here we decide will be used to indicate the “endianness” of the bytes); and the SChunk instance which hosts the compressed block. The encoder must then return the size of the compressed buffer in bytes. If
it cannot compress the data, it must return 0 - Blosc2 will then know to simply copy the block without compressing. The image below depicts what our encoder does:
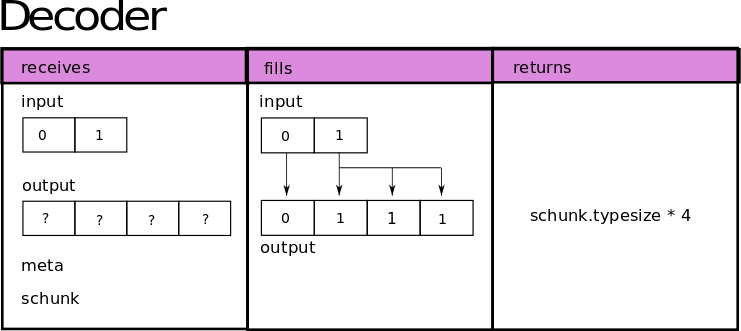
Now let’s go for the decoder, which also expects to receive the same 4 arguments, and operates blockwise.
[3]:
def decoder(input, output, meta, schunk):
byteorder = "little" if meta == 0 else "big"
if byteorder == "little":
nd_input = input.view("<i4")
else:
nd_input = input.view(">i4")
nd_output = output.view("i4")
nd_output[0 : nd_input[1]] = [nd_input[0]] * nd_input[1]
return nd_input[1] * schunk.typesize
The decoder function must return the size of the decompressed buffer in bytes; it receives the output filled by the encoder as the input param, and will recreate the data again following this scheme:
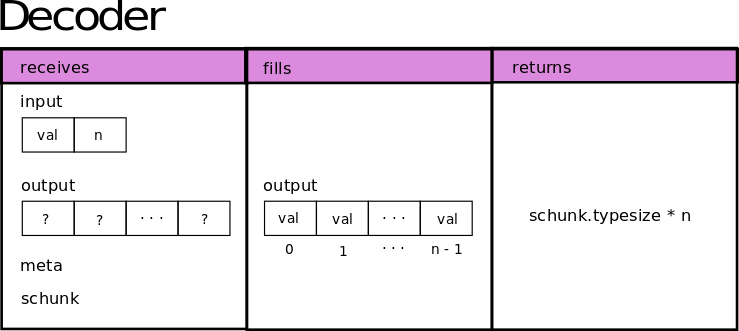
Note that if a block was memcopied (uncompressed) by Blosc2 the decoder will be skipped when requesting data from the SChunk.
Registering and Using a codec¶
Once the codec’s procedures are defined, we can register it to the local Blosc2 codec registry! For that, we must choose an identifier between 160 and 255.
[4]:
codec_name = "our_codec"
codec_id = 160
blosc2.register_codec(codec_name, codec_id, encoder, decoder)
The codec can now be specified in the compression params of an SChunk instance using its id. We also pass the codec_meta that we want our codec to use in the encoder and decoder. Since we designed the codec to receive the original data with no changes, we specify that no filters are to be used:
[5]:
codec_meta = 0 if sys.byteorder == "little" else 1
for k, v in {
"codec": codec_id,
"codec_meta": codec_meta,
"filters": [blosc2.Filter.NOFILTER],
"filters_meta": [0],
}.items():
setattr(cparams, k, v)
schunk.cparams = cparams
schunk.cparams
[5]:
CParams(codec=160, codec_meta=0, clevel=1, use_dict=False, typesize=4, nthreads=1, blocksize=0, splitmode=<SplitMode.AUTO_SPLIT: 3>, filters=[<Filter.NOFILTER: 0>, <Filter.NOFILTER: 0>, <Filter.NOFILTER: 0>, <Filter.NOFILTER: 0>, <Filter.NOFILTER: 0>, <Filter.NOFILTER: 0>], filters_meta=[0, 0, 0, 0, 0, 0], tuner=<Tuner.STUNE: 0>)
Note that it is important to update the whole cparams attribute at the same time, and not the individual attributes e.g. cparams.codec, since the latter do not have setters defined (whereas SChunk does have a cparams setter defined), and so will not update the compression parameters correctly; i.e. schunk.cparams.codec = 160 will not correctly update the internal C machinery. Now we can check that our codec works well by appending and recovering some data, composed of three
chunks, each of which is made of a different repeated value - the compression goes blockwise, so many blocks will be composed of a single repeated value and will be compressed by the codec.
[6]:
fill_value = 1234
a = np.full(chunk_len, fill_value, dtype=dtype)
b = np.full(chunk_len, fill_value + 1, dtype=dtype)
c = np.full(chunk_len, fill_value + 2, dtype=dtype)
data = np.concat((a, b, c))
schunk[0 : data.size] = data
print("schunk cratio: ", round(schunk.cratio, 2))
out = np.empty(data.shape, dtype=dtype)
schunk.get_slice(out=out)
np.array_equal(data, out)
schunk cratio: 83.33
[6]:
True
Awesome, it works! However, if the array is not composed of blocks with repeated values our codec will not compress anything. In the next section, we will create and use a filter and perform a little modification to our codec so that we can compress even if the data is made out of equally spaced values.
User-defined filters¶
Writing and registering filters is not too different to writing and registering codecs. Filters do not directly compress data, but rather manipulate it to make it easier to compress.
Creating a filter¶
As for user-defined codecs, to create a user-defined filter we will first need to create two functions: one for the compression process (aka forward) and another one for the decompression process (aka backward).
Let’s write first the forward function. Its signature is exactly the same as the encoder/decoder signature, although here the meta will be passed from the filters_meta attribute of the CParams instance associated to schunk (which does not necessarily have to be used). Neither the forward nor backward functions have to return anything.
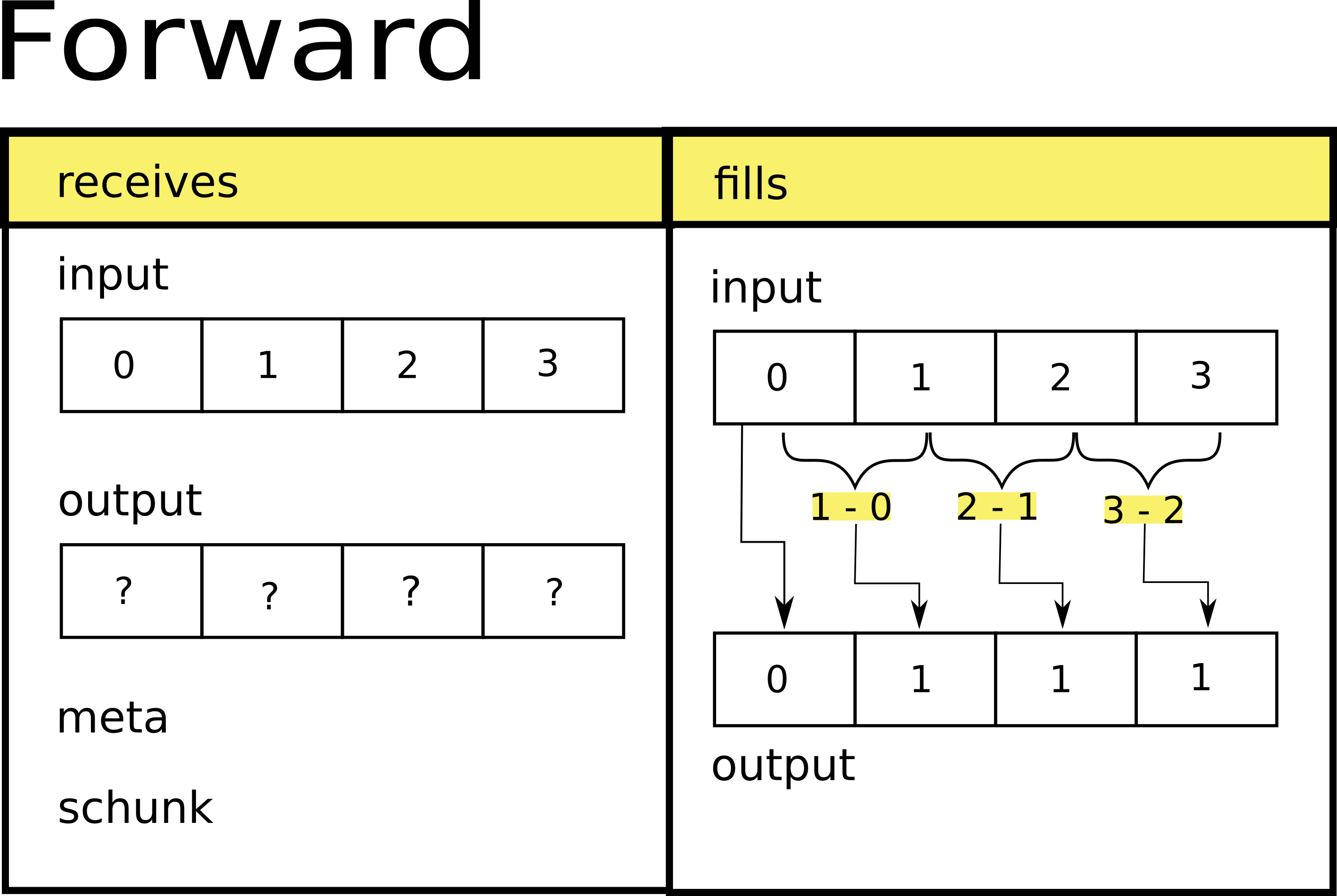
[7]:
def forward(input, output, meta, schunk):
nd_input = input.view(dtype)
nd_output = output.view(dtype)
start = nd_input[0]
nd_output[0] = start
nd_output[1:] = nd_input[1:] - nd_input[:-1]
As you can see, our forward function keeps the start value, and then it computes the difference between each element and the one next to it just like the following image shows. As a consequence, after passing through the filter, equally spaced data will be processed into an array with many repeated values. Later on, we will write a new codec which will be able to compress/decompress this filtered data.
The backward function applies the inverse transform to the forward function, so it will reconstruct the original data.
[8]:
def backward(input, output, meta, schunk):
nd_input = input.view(dtype)
nd_output = output.view(dtype)
nd_output[0] = nd_input[0]
for i in range(1, nd_output.size):
nd_output[i] = nd_output[i - 1] + nd_input[i]
Hence when called on the output of the forward function, it will reconstruct the original data as follows:
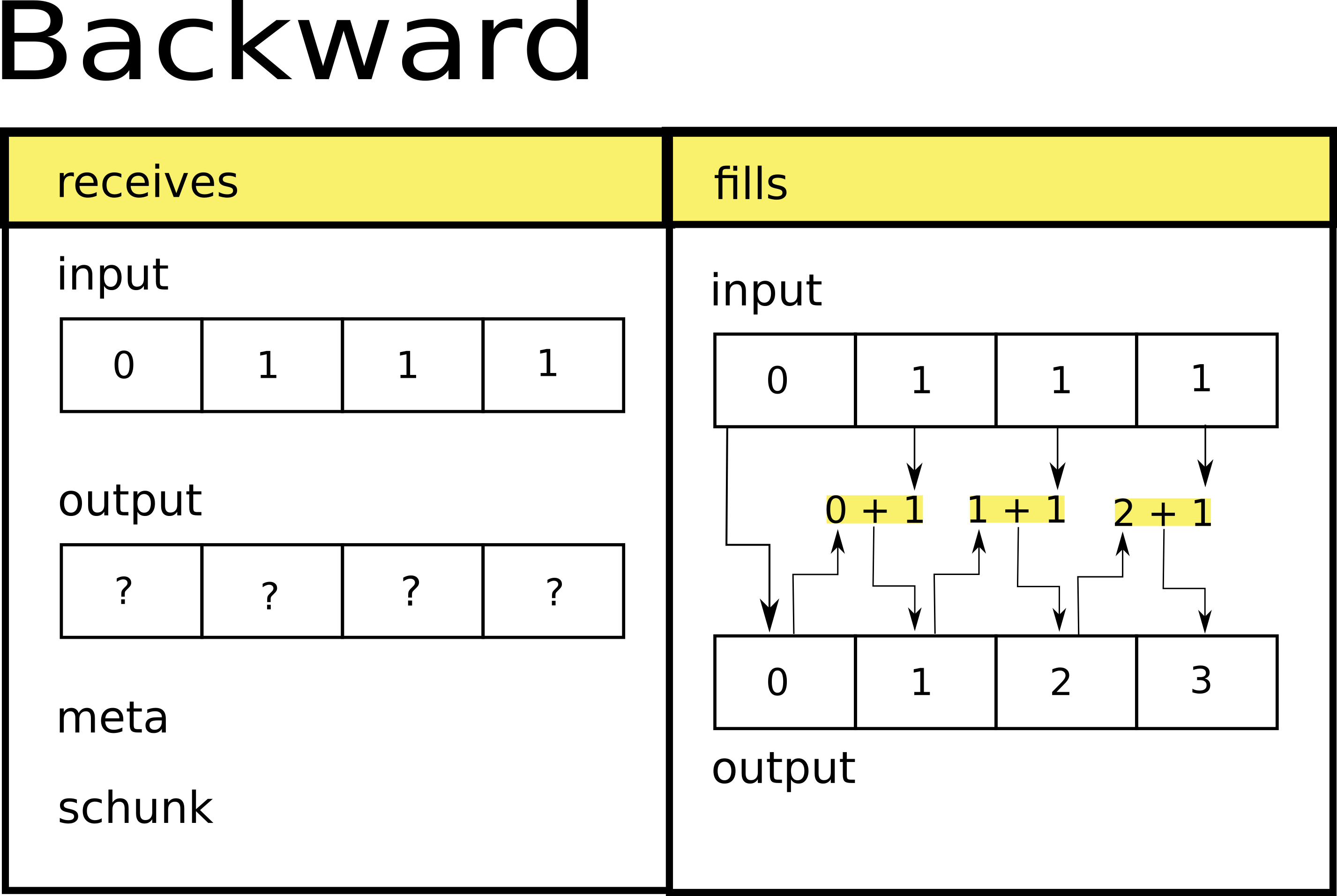
Registering and Using a filter¶
Once we have the two required functions, we can register our filter. In the same way we did for the codecs, we have to choose an identifier between 160 and 255:
[9]:
filter_id = 160
blosc2.register_filter(filter_id, forward, backward)
The filter can now be introduced into the SChunk’s filter pipeline via updating the cparams attribute of the SChunk instance with a list of the filters to be applied, indicated by their unique id (in this case just the filter we created), and their corresponding filters_meta (in this case it is unimportant, as the filter does not use it). We also need to update the codec used so that we can take advantage of the filter first though.
Writing a new codec for the filtered data¶
Next, we are going to create another codec to compress data passed by the filter. This will get the start value and the step when compressing, and will rebuild the data from those values when decompressing:
[10]:
def encoder2(input, output, meta, schunk):
nd_input = input.view(dtype)
if np.min(nd_input[1:]) == np.max(nd_input[1:]):
output[0 : schunk.typesize] = input[0 : schunk.typesize] # start
step = int(nd_input[1])
n = step.to_bytes(4, sys.byteorder)
output[schunk.typesize : schunk.typesize + 4] = [n[i] for i in range(4)]
return schunk.typesize + 4
else:
# Not compressible, tell Blosc2 to do a memcpy
return 0
def decoder2(input, output, meta, schunk):
nd_input = input.view(dtype)
nd_output = output.view(dtype)
nd_output[0] = nd_input[0]
nd_output[1:] = nd_input[1]
return nd_output.size * schunk.typesize
Their corresponding schemes are as follows:
As the previous id is already in use, we will register it with another identifier:
[11]:
blosc2.register_codec(codec_name="our_codec2", id=184, encoder=encoder2, decoder=decoder2)
Now we update the schunk’s cparams to use the new codec as well as the filter we just registered. We will also set the codec_meta to 0, although it isn’t used by our new codec.
[12]:
cparams.filters = [filter_id]
cparams.filters_meta = [0]
cparams.codec = 184
cparams.codec_meta = 0
schunk.cparams = cparams
schunk.cparams
[12]:
CParams(codec=184, codec_meta=0, clevel=1, use_dict=False, typesize=4, nthreads=1, blocksize=0, splitmode=<SplitMode.AUTO_SPLIT: 3>, filters=[160, <Filter.NOFILTER: 0>, <Filter.NOFILTER: 0>, <Filter.NOFILTER: 0>, <Filter.NOFILTER: 0>, <Filter.NOFILTER: 0>], filters_meta=[0, 0, 0, 0, 0, 0], tuner=<Tuner.STUNE: 0>)
We will check that it actually works by updating the data:
[13]:
nchunks = 3
new_data = np.arange(chunk_len, chunk_len * (nchunks + 1), dtype=dtype)
schunk[0 : new_data.size] = new_data
print("schunk compression ratio: ", round(schunk.cratio, 2))
out = np.empty(new_data.shape, dtype=dtype)
schunk.get_slice(out=out)
np.array_equal(new_data, out)
schunk compression ratio: 83.33
[13]:
True
As can be seen, we obtained the same compression ratio as before - since we store each of the 3 chunks using 8 bytes each.
Conclusion and NDArray arrays¶
So now, whenever you need it, you can register a codec or filter and use it in your data! Note that one can also define and apply codecs and filters to blosc2.NDArray objects, since they are based on the SChunk class, like so:
[14]:
array = blosc2.zeros((30, 30))
array.schunk.cparams = blosc2.CParams(codec=184, filters=[filter_id], filters_meta=[0], nthreads=1)
array.schunk.cparams
[14]:
CParams(codec=184, codec_meta=0, clevel=1, use_dict=False, typesize=8, nthreads=1, blocksize=0, splitmode=<SplitMode.AUTO_SPLIT: 3>, filters=[160, <Filter.NOFILTER: 0>, <Filter.NOFILTER: 0>, <Filter.NOFILTER: 0>, <Filter.NOFILTER: 0>, <Filter.NOFILTER: 0>], filters_meta=[0, 0, 0, 0, 0, 0], tuner=<Tuner.STUNE: 0>)