User-defined codecs and filters#
Python-Blosc2 now has support for user-defined codecs and filters as Python functions. These will work as normal codecs or filters respectively following the order depicted below:
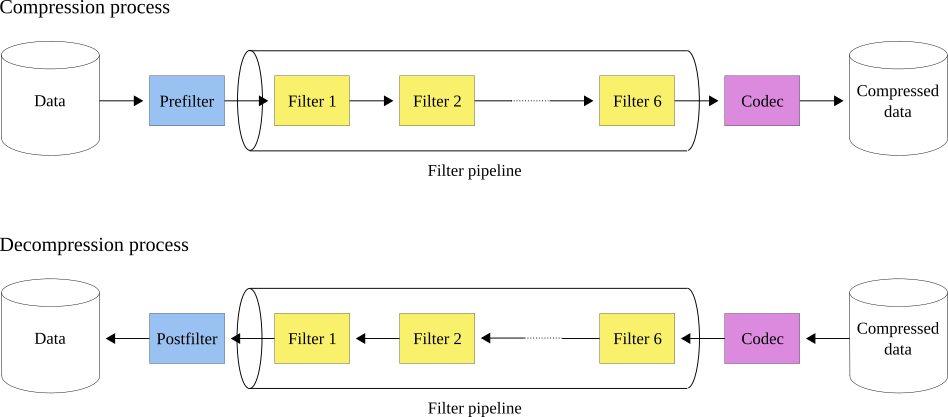
So when compressing, the first step will be to apply the prefilter (if any), then the filter pipeline with a maximum of six filters and, last but not least, the codec. For decompressing, the order will be the other way around: first the codec, then the filter pipeline and finally the postfilter (if any).
In this tutorial we will see how to create and use codecs and filters defined by yourself, so let’s start by creating our schunk!
User-defined codecs#
Because a user-defined codec has Python code, we will not be able to use parallelism, so nthreads has to be 1 when compressing and decompressing:
[1]:
import sys
import numpy as np
import blosc2
dtype = np.dtype(np.int32)
cparams = blosc2.CParams(nthreads=1, typesize=dtype.itemsize)
dparams = blosc2.DParams(nthreads=1)
chunk_len = 10_000
schunk = blosc2.SChunk(chunksize=chunk_len * dtype.itemsize, cparams=cparams)
Creating a codec#
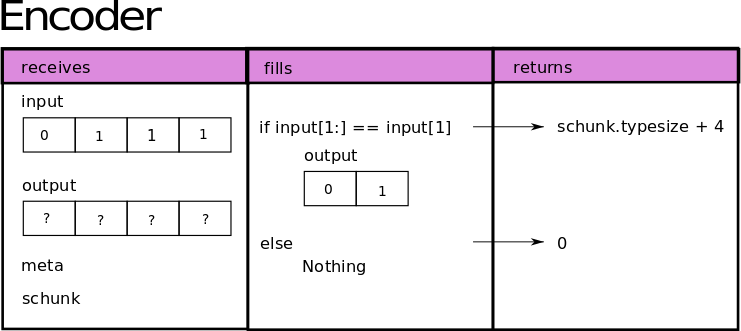
To create a codec we need two functions: one for compressing (aka encoder) and another for decompressing (aka decoder). In this case, we will create a codec for repeated values, let’s begin first with the encoder function:
[2]:
def encoder(input, output, meta, schunk):
nd_input = input.view(dtype)
# Check if all the values are the same
if np.max(nd_input) == np.min(nd_input):
# output = [value, nrep]
output[0 : schunk.typesize] = input[0 : schunk.typesize]
byteorder = "little" if meta == 0 else "big"
n = nd_input.size.to_bytes(4, byteorder)
output[schunk.typesize : schunk.typesize + 4] = [n[i] for i in range(4)]
return schunk.typesize + 4
else:
# memcpy
return 0
This function will receive the data input to compress as a ndarray of type uint8, the output to fill in the compressed buffer as a ndarray of type uint8 as well, the codec meta and the SChunk instance of the corresponding block that is being compressed. Furthermore, encoder must return the size of the compressed buffer in bytes. If it cannot compress the data, it must return 0 and Blosc2 will copy it. The image below depicts what our encoder does:
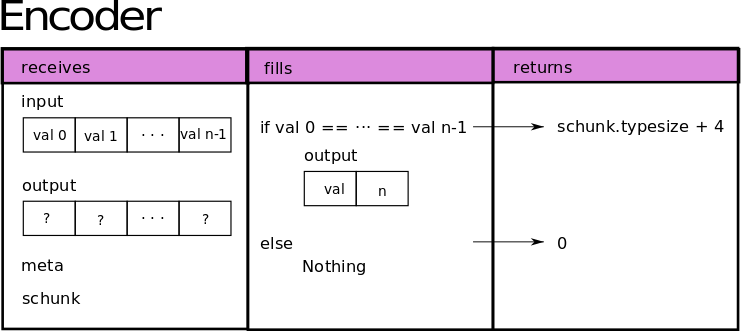
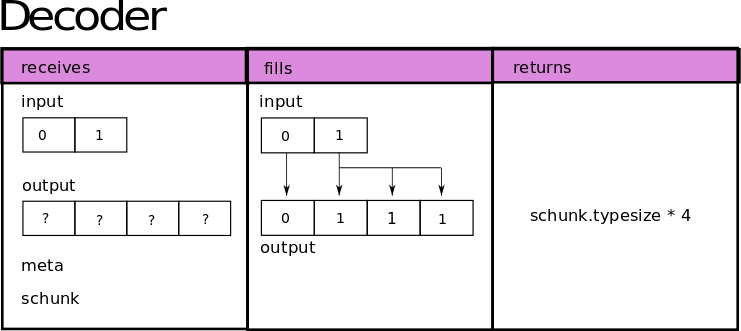
Now let’s go for the decoder. Similarly to the previous function, it will receive the compressed input as a ndarray of type uint8, an output ndarray of type uint8 to fill it with the decompressed data, the codec meta and the corresponding SChunk instance as well.
[3]:
def decoder(input, output, meta, schunk):
byteorder = "little" if meta == 0 else "big"
if byteorder == "little":
nd_input = input.view("<i4")
else:
nd_input = input.view(">i4")
nd_output = output.view("i4")
nd_output[0 : nd_input[1]] = [nd_input[0]] * nd_input[1]
return nd_input[1] * schunk.typesize
As it is for decompressing, this function will return the size of the decompressed buffer in bytes. If a block was memcopied by Blosc2, it will take care of it without applying the decoder. This function will receive the output filled by the encoder as the input param, and will recreate the data again following this scheme:
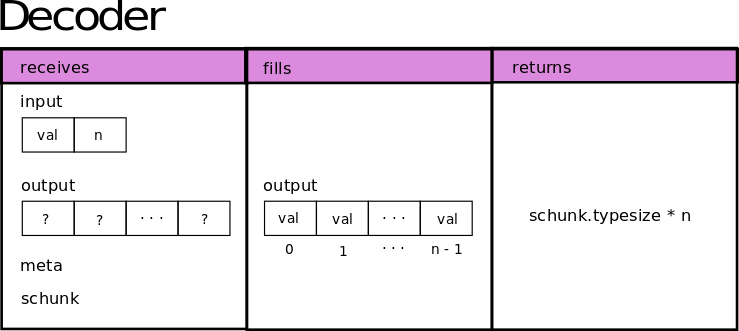
Registering a codec#
Now that we have everything needed, we can register our codec! For that, we will choose an identifier between 160 and 255.
[4]:
codec_name = "our_codec"
codec_id = 160
blosc2.register_codec(codec_name, codec_id, encoder, decoder)
Using a codec#
For actually using it, we will change our codec in the compression params using its id and, because in our particular case we want the codec to receive the original data with no changes, we will remove also the filters:
[8]:
codec_meta = 0 if sys.byteorder == "little" else 1
schunk.cparams = {
"codec": codec_id,
"codec_meta": codec_meta,
"filters": [blosc2.Filter.NOFILTER],
"filters_meta": [0],
}
schunk.cparams
[8]:
{'codec': 160,
'codec_meta': 0,
'clevel': 1,
'use_dict': 0,
'typesize': 4,
'nthreads': 1,
'blocksize': 0,
'splitmode': <SplitMode.ALWAYS_SPLIT: 1>,
'filters': [<Filter.NOFILTER: 0>,
<Filter.NOFILTER: 0>,
<Filter.NOFILTER: 0>,
<Filter.NOFILTER: 0>,
<Filter.NOFILTER: 0>,
<Filter.NOFILTER: 0>],
'filters_meta': [0, 0, 0, 0, 0, 0]}
“Now we can check that our codec works well by appending and recovering some data:
[6]:
nchunks = 3
fill_value = 1234
data = np.full(chunk_len * nchunks, fill_value, dtype=dtype)
schunk[0 : data.size] = data
print("schunk cratio: ", round(schunk.cratio, 2))
out = np.empty(data.shape, dtype=dtype)
schunk.get_slice(out=out)
np.array_equal(data, out)
schunk cratio: 476.19
[6]:
True
Awesome, it works!
However, if the values are not the same our codec will not compress anything. In the next section, we will create and use a filter and perform a little modification to our codec so that we can compress even if the data is made out of equally spaced values.
User-defined filters#
Once you get to do some codecs, filters are not different despite their goal is not to compress but to manipulate the data to make it easier to compress.
Creating a filter#
As for the codecs, to create a user-defined filter we will first need to create two functions: one for the compression process (aka forward) and another one for the decompression process (aka backward).
Let’s write first the forward function. Its signature is exactly the same as the encoder signature, the only difference is that the meta is the filter’s meta. Regarding the return value though, the forward and backward functions do not have to return anything.
[7]:
def forward(input, output, meta, schunk):
nd_input = input.view(dtype)
nd_output = output.view(dtype)
start = nd_input[0]
nd_output[0] = start
nd_output[1:] = nd_input[1:] - nd_input[:-1]
As you can see, our forward function keeps the start value, and then it computes the difference between each element and the one next to it just like the following image shows:
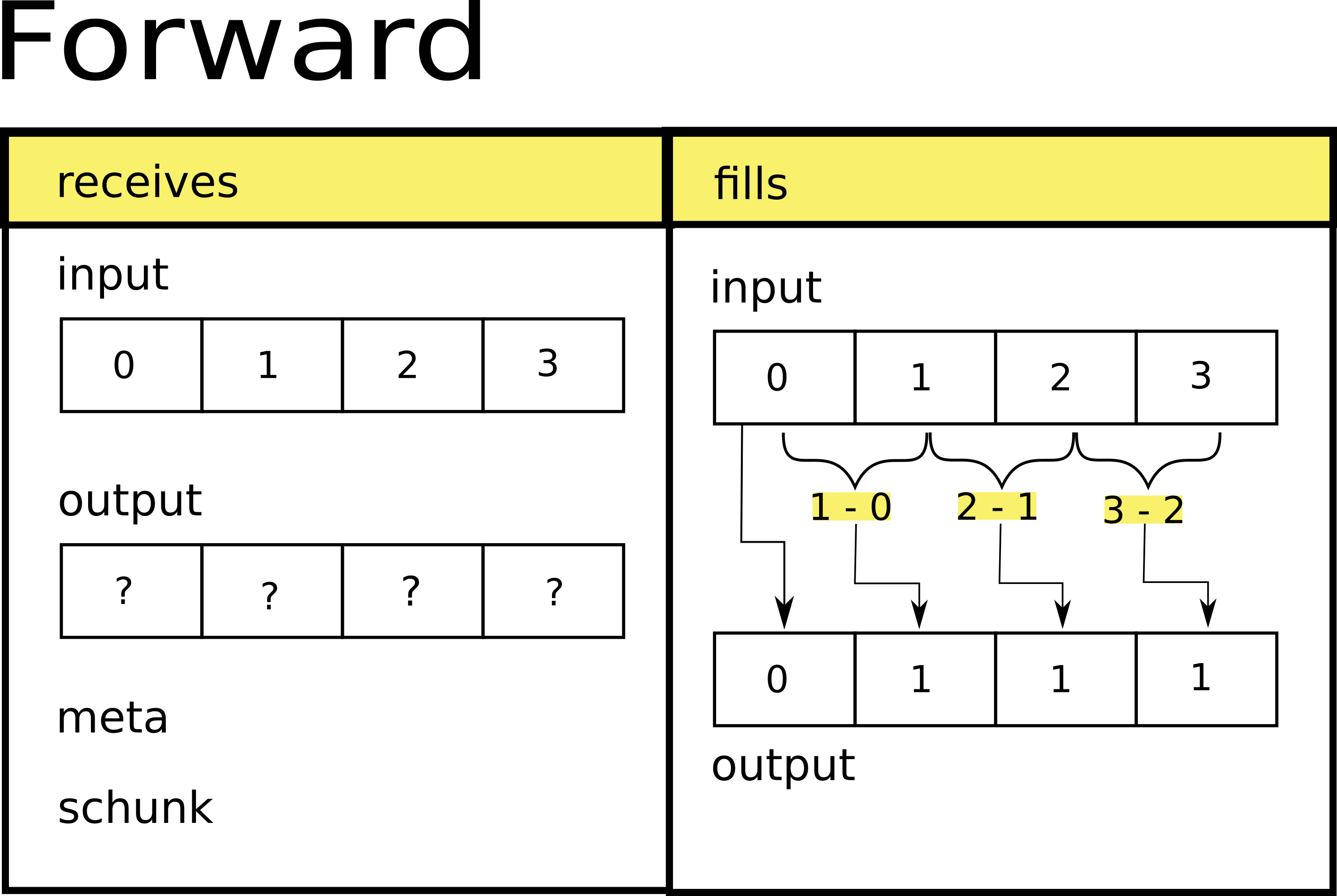
For backward it happens something similar:
[8]:
def backward(input, output, meta, schunk):
nd_input = input.view(dtype)
nd_output = output.view(dtype)
nd_output[0] = nd_input[0]
for i in range(1, nd_output.size):
nd_output[i] = nd_output[i - 1] + nd_input[i]
And its scheme will be:
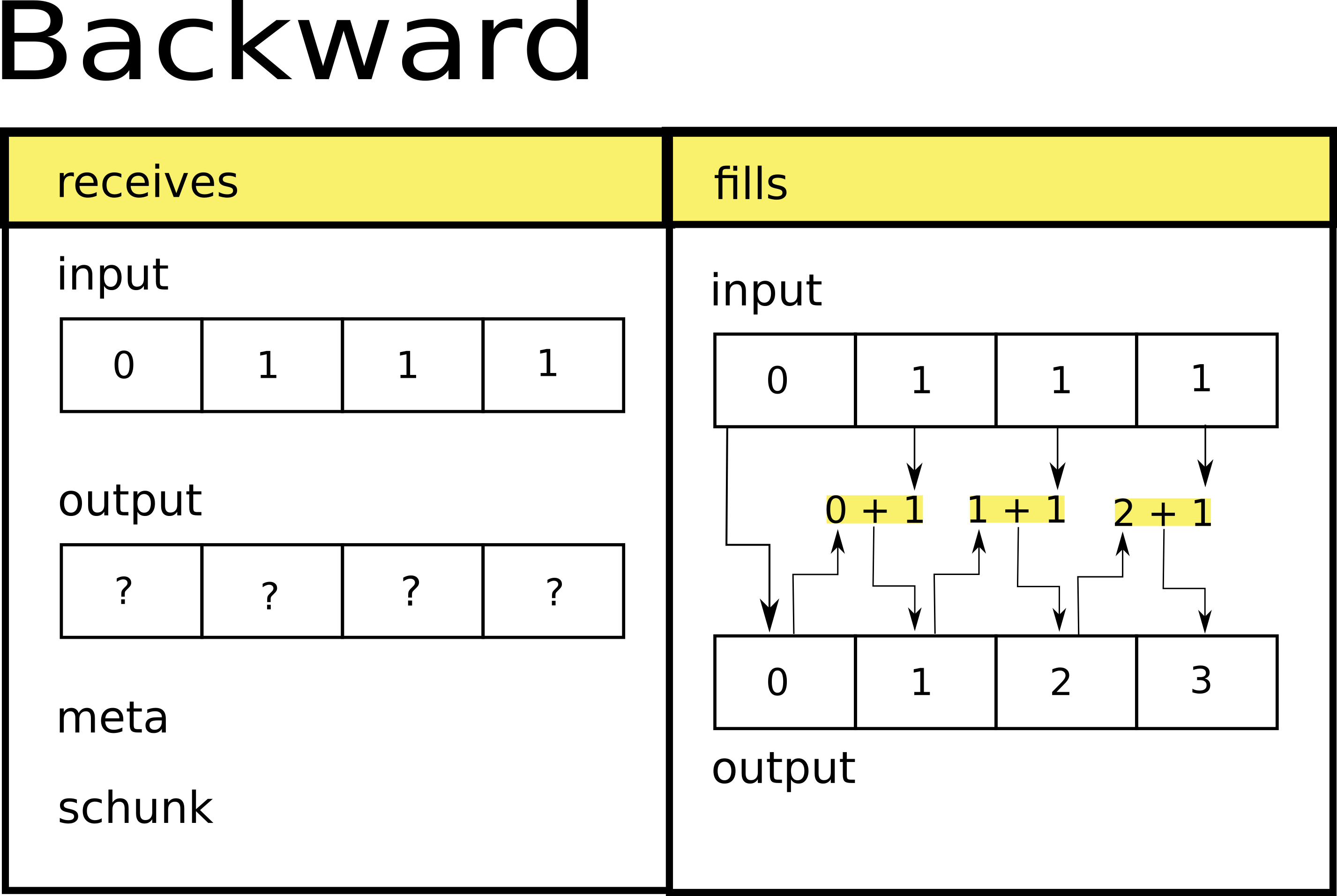
Registering a filter#
Once we have the two required functions, we can register our filter. In the same way we did for the codecs, we have to choose an identifier between 160 and 255:
[9]:
filter_id = 160
blosc2.register_filter(filter_id, forward, backward)
Using a filter in a SChunk#
To use the filter we will set it in the filter pipeline using its id:
[10]:
schunk.cparams = {"filters": [filter_id], "filters_meta": [0]}
schunk.cparams
[10]:
{'codec': 160,
'codec_meta': 0,
'clevel': 1,
'use_dict': 0,
'typesize': 4,
'nthreads': 1,
'blocksize': 0,
'splitmode': <SplitMode.ALWAYS_SPLIT: 1>,
'filters': [160,
<Filter.NOFILTER: 0>,
<Filter.NOFILTER: 0>,
<Filter.NOFILTER: 0>,
<Filter.NOFILTER: 0>,
<Filter.NOFILTER: 0>],
'filters_meta': [0, 0, 0, 0, 0, 0]}
Using a filter in a NDArray#
As for the NDArrays, the procedure will be the same: To use the filter we will set it in the filter pipeline using its id:
[11]:
array = blosc2.zeros((30, 30))
array.schunk.cparams = {"filters": [filter_id], "filters_meta": [0], "nthreads": 1}
array.schunk.cparams
[11]:
{'codec': <Codec.ZSTD: 5>,
'codec_meta': 0,
'clevel': 1,
'use_dict': 0,
'typesize': 1,
'nthreads': 1,
'blocksize': 900,
'splitmode': <SplitMode.ALWAYS_SPLIT: 1>,
'filters': [160,
<Filter.NOFILTER: 0>,
<Filter.NOFILTER: 0>,
<Filter.NOFILTER: 0>,
<Filter.NOFILTER: 0>,
<Filter.NOFILTER: 0>],
'filters_meta': [0, 0, 0, 0, 0, 0]}
Next, we are going to create another codec to compress data passed by the filter. This will get the start value and the step when compressing, and will rebuild the data from those values when decompressing:
[12]:
def encoder2(input, output, meta, schunk):
nd_input = input.view(dtype)
if np.min(nd_input[1:]) == np.max(nd_input[1:]):
output[0:4] = input[0:4] # start
step = int(nd_input[1])
n = step.to_bytes(4, sys.byteorder)
output[4:8] = [n[i] for i in range(4)]
return 8
else:
# Not compressible, tell Blosc2 to do a memcpy
return 0
def decoder2(input, output, meta, schunk):
nd_input = input.view(dtype)
nd_output = output.view(dtype)
nd_output[0] = nd_input[0]
nd_output[1:] = nd_input[1]
return nd_output.size * schunk.typesize
Their corresponding schemes are as follows:
As the previous id is already in use, we will register it with another identifier:
[13]:
blosc2.register_codec(codec_name="our_codec2", id=184, encoder=encoder2, decoder=decoder2)
As done previously, we set it first to the SChunk instance:
[14]:
schunk.cparams = {
"codec": 184,
"codec_meta": 0,
}
We will check that it actually works by updating the data:
[15]:
new_data = np.arange(chunk_len, chunk_len * (nchunks + 1), dtype=dtype)
schunk[:] = new_data
print("schunk's compression ratio: ", round(schunk.cratio, 2))
out = np.empty(new_data.shape, dtype=dtype)
schunk.get_slice(out=out)
np.array_equal(new_data, out)
schunk's compression ratio: 476.19
[15]:
True
As can be seen, we obtained a stunning compression ratio.
So now, whenever you need it, you can register a codec or filter and use it in your data!