Blosc2: A Universal Lazy Engine for Array Operations
While compression is often seen merely as a way to save storage, the Blosc development team has long viewed it as a foundational element for high-performance computing. This philosophy is at the heart of Blosc2, which is not just a compression library but a powerful framework for handling large datasets. This post will highlight one of Python-Blosc2's most exciting capabilities: its lazy evaluation engine for array operations.
Libraries optimised for computation on large datasets that don't fit in memory - such as Dask or Spark - often use lazy evaluation of computation expressions. This typically speeds up evaluation since one can build the full chain of computations and only execute them when the final result is needed. Consequently, Python-Blosc2's compute engine also uses the lazy imperative paradigm, which proves to be both powerful and efficient.
An additional benefit of the engine is its ability to act as a universal backend. Python-Blosc2 has a native blosc2.NDArray format, but it can also easily execute lazy operations on arrays from other popular libraries like NumPy, HDF5, Zarr, Xarray or TileDB - basically any array object which complies with a minimal protocol.
In the recent Python-Blosc2 3.10.x series, we added support for lazy evaluation of eager functions, expanding the capabilities of the compute engine, and making interaction with other formats easier. Let's explore how this works using an out-of-core tensordot operation as an example.
From Eager to Lazy with blosc2.lazyexpr
Functions which return a result with a different shape to the input operands - such as reductions or linear algebra operations - must be evaluated eagerly (computed and the result returned immediately). For example, blosc2.tensordot() executes eagerly.
Nevertheless, we can defer this computation, by wrapping the call in a string and passing it to blosc2.lazyexpr. This creates a LazyExpr object that represents the operation without executing it.
# Assume a and b are large, on-disk blosc2 arrays axis = (0, 1) # Create a lazy expression object lexpr = blosc2.lazyexpr("tensordot(a, b, axes=(axis, axis))") # The computation has not run yet. # To execute it and save the result to a new persistent array: out_blosc2 = lexpr.compute(urlpath="out.b2nd", mode="w")
This is useful, and highly efficient both in terms of computation time and memory usage, as we'll see later. But the real magic happens when we use this computation engine with other array formats.
One Engine, Many Backends
The blosc2.evaluate() function takes the same string expression but can operate on any array-like objects that follow the blosc2.Array protocol. This protocol simply requires the object to have shape, dtype, __getitem__, and __setitem__ attributes, which are standard in h5py, zarr, tiledb, xarray and numpy arrays.
This means you can use Blosc2's efficient evaluation engine to perform out-of-core computations directly on your existing (HDF5, Zarr, etc.) datasets.
Example with HDF5
Here, we instruct blosc2.evaluate to run the tensordot operation on two h5py datasets and store the result in a third one.
# Open HDF5 datasets f = h5py.File("a_b_out.h5", "a") a = f["a"] b = f["b"] out_hdf5 = f["out"] # Use blosc2.evaluate() with HDF5 arrays blosc2.evaluate("tensordot(a, b, axes=(axis, axis))", out=out_hdf5)
Notice that the expression string is identical to the one we used before. blosc2 inspects the objects in the expression's namespace and computes with them, regardless of their underlying format.
Example with Zarr
The same principle applies to Zarr arrays.
# Open Zarr arrays a = zarr.open("a.zarr", mode="r") b = zarr.open("b.zarr", mode="r") zout = zarr.open_array("out.zarr", mode="w", ...) # Use blosc2.evaluate() with Zarr arrays blosc2.evaluate("tensordot(a, b, axes=(axis, axis))", out=zout)
This makes blosc2.evaluate a powerful, backend-agnostic tool for out-of-core array computations.
Performance Comparison
As well as offering smooth integration, blosc2.evaluate is highly performant. Python-Blosc2 uses a lazy evaluation engine that integrates tightly with the Blosc2 format. This means that the computation is performed on-the-fly, without any intermediate copies. This is a huge advantage for large datasets, as it allows us to perform computations on arrays that don't fit in memory. In addition, it actively tries to leverage the hierarchical memory layout in modern CPUs, so that it can use both private and shared caches in the best way possible.
We ran a benchmark performing a tensordot operation (run over three different axis combinations) on two 3D arrays stored on disk; we then write the output to disk as well.
We consider four approaches:
Blosc2 Native: Using
blosc2.lazyexprwithblosc2.NDArraycontainers.Blosc2+HDF5: Using
blosc2.evaluatewith HDF5 for storage.Blosc2+Zarr: Using
blosc2.evaluatewith Zarr for storage.Dask+HDF5: The combination of Dask for computation and HDF5 for storage.
Dask+Zarr: The combination of Dask for computation and Zarr for storage.
For each approach we plot the memory consumption vs. time for arrays of increasing size.
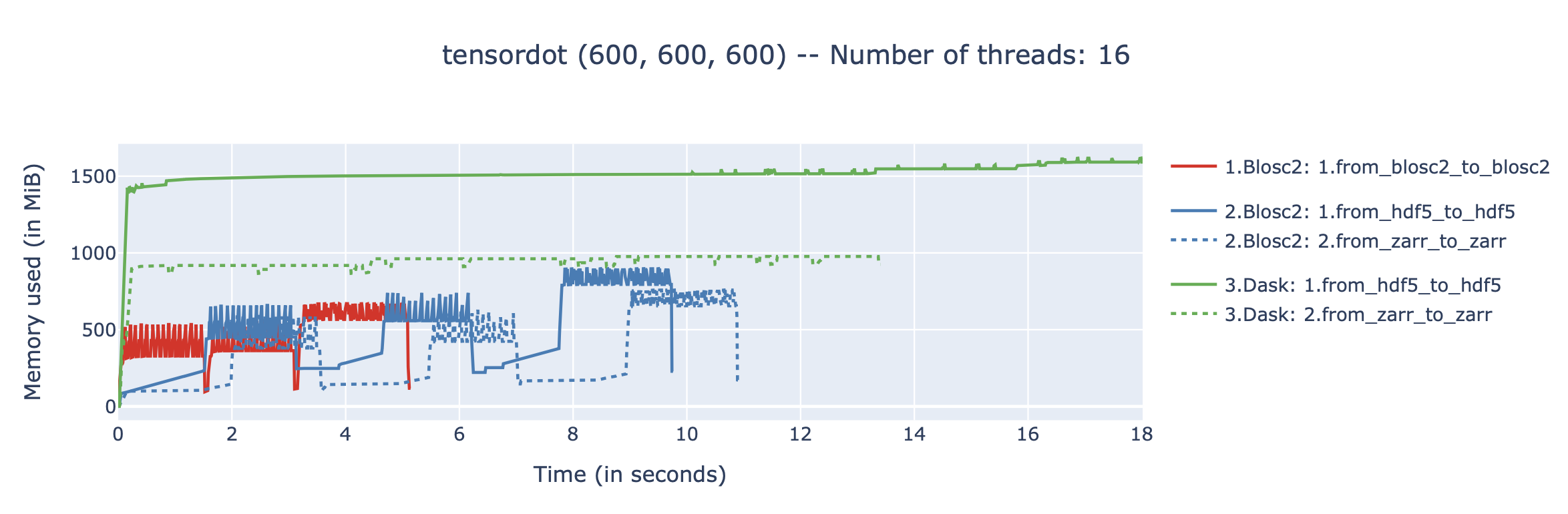
Results on two (600, 600, 600) float64 arrays (3 GB working set):
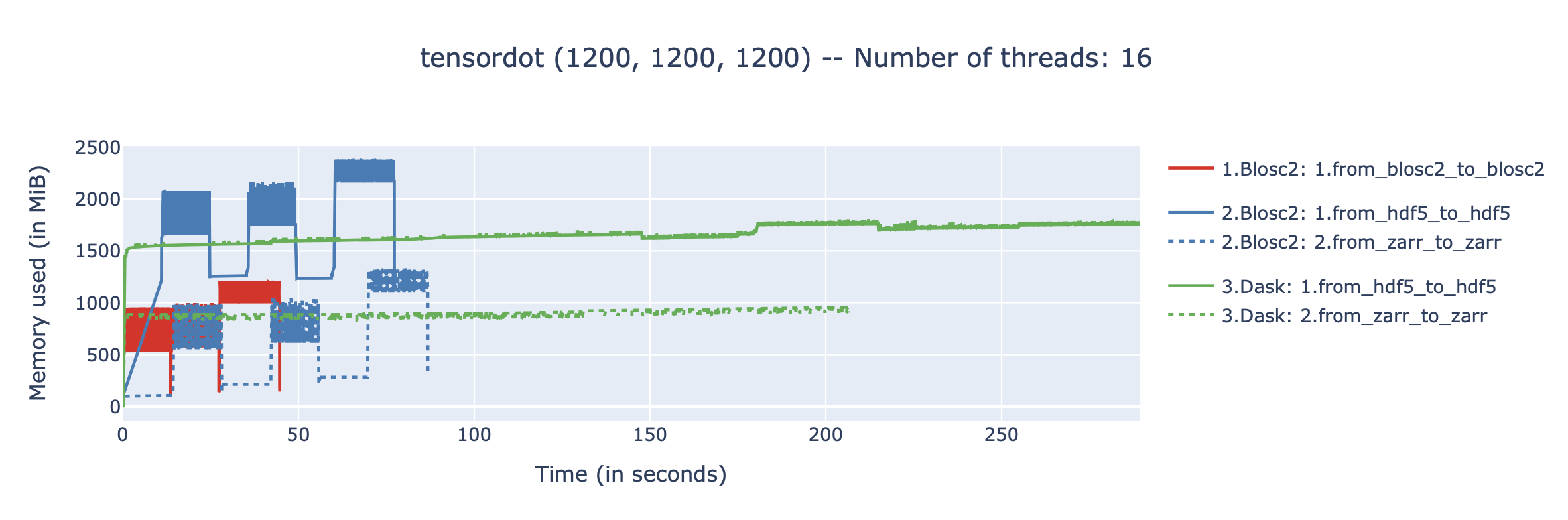
Results on two (1200, 1200, 1200) float64 arrays (26 GB working set):
Results on two (1500, 1500, 1500) float64 arrays (50 GB working set):
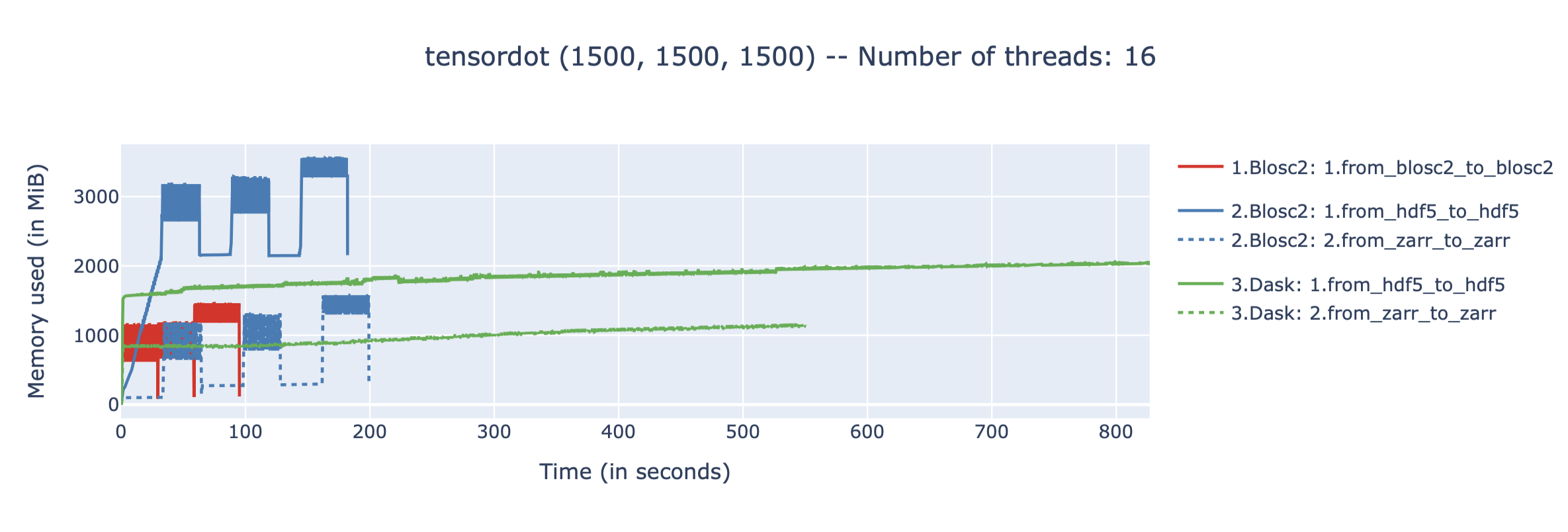
As can be seen, the amount of memory required by the different approaches is very different, although none requires more than a small fraction of the total working set (which is 3, 26 and 50 GB, respectively). This is because all approaches are out-of-core, and only load small chunks of data into memory at any given time.
The benchmarks were executed on an AMD Ryzen 9800X3D CPU, with 16 logical cores and 64GB of RAM, using Ubuntu Linux 25.04. We have used the following versions of the libraries: python-blosc2 3.10.1, h5py 3.14.0, zarr 3.1.3, 2025.9.1, and numpy 2.3.3. All backends are using Blosc or Blosc2 as the compression backend, with same codecs and filters, and using the same number of threads for compression and decompression.
Analysis
The results are revealing:
Blosc2 native is fastest: The tight integration between the Blosc2 compute engine and its native array format yields the best performance, making it the fastest solution by a significant margin.
Rapid computation time:
blosc2.evaluatedelivers impressive speed when operating directly on HDF5 and Zarr files, outperforming the more complex Dask+HDF5 and Dask+Zarr stack. This is great news for anyone with existing HDF5/Zarr datasets.Low memory usage: While the memory consumption for the Blosc2+HDF5 combination is a bit high (we are still analyzing why), the memory usage for the Blosc2 native approach is pretty low, making it suitable for systems with limited RAM and/or operands not fitting in memory.
This is not to say that Dask (or Spark) is an inferior choice for out-of-core computations. It's a great tool for large-scale data processing, especially when using clusters, is very flexible, and offers a wide range of functions; it's certainly a first-class citizen in the PyData ecosystem. However, if your needs are more modest and you want a simple, efficient way to run computations on existing datasets, using a core of common functions, and leveraging the full capabilities of modern multi-core systems, all without the overhead of a full Dask setup, blosc2.evaluate() is a fantastic alternative.
Conclusion
Python-Blosc2 is more than just a compression library for storing data in blosc2.NDArray objects; it's a high-performance computing tool as well. Its lazy evaluation engine provides a simple yet powerful way to handle out-of-core operations. The computation engine is completely decoupled from the compression backend, and thus can easily work with many different array formats; however, the compute engine meshes most tightly with the Blosc2 native array format, achieving maximal performance (in terms of both computation time and memory usage).
By adhering to the Array API standard, it acts as a universal engine that can work with different storage backends; we already implement more than 100 functions that are required by that standard, and the number will only grow in the future. If you have existing datasets in HDF5 or Zarr or TileDB (and we are always looking forward to support even more formats), and need a lightweight, efficient way to run computations on them, blosc2.evaluate() is a fantastic tool to have in your arsenal. Of course, for maximum performance, the native Blosc2 format is a clear winner.
Our work continues. We are committed to enhancing Python-Blosc2 by expanding its supported operations, improving performance across backends, and adding new ones. Stay tuned for more updates! If you found this post useful, please share it. For questions or comments, reach out to us on GitHub.
Comments
Comments powered by Disqus