Make NDArray Transposition Fast (and Compressed!) within Blosc 2
Update (2025-04-30): The transpose function is now officially deprecated and
replaced by the new permute_dims. This transition follows the Python array
API standard v2022.12, aiming to make Blosc2 even more compatible with modern
Python libraries and workflows.
In contrast with the previous transpose, the new permute_dims offers:
Support for arrays of any number of dimensions.
Full handling of arbitrary axis permutations, including support for negative indices.
Moreover, I have found a new way to transpose matrices more efficiently for Blosc2. This blog contains updated plots and discussions.
---
Matrix transposition is more than a textbook exercise, it plays a key role in memory-bound operations where layout and access patterns can make or break performance.
When working with large datasets, efficient data transformation can significantly improve both performance and compression ratios. In Blosc2, we recently implemented a matrix transposition function, a fundamental operation that rearranges data by swapping rows and columns. In this post, I'll share the design insights, implementation details, performance considerations that went into this feature, and an unexpected NumPy behaviour.
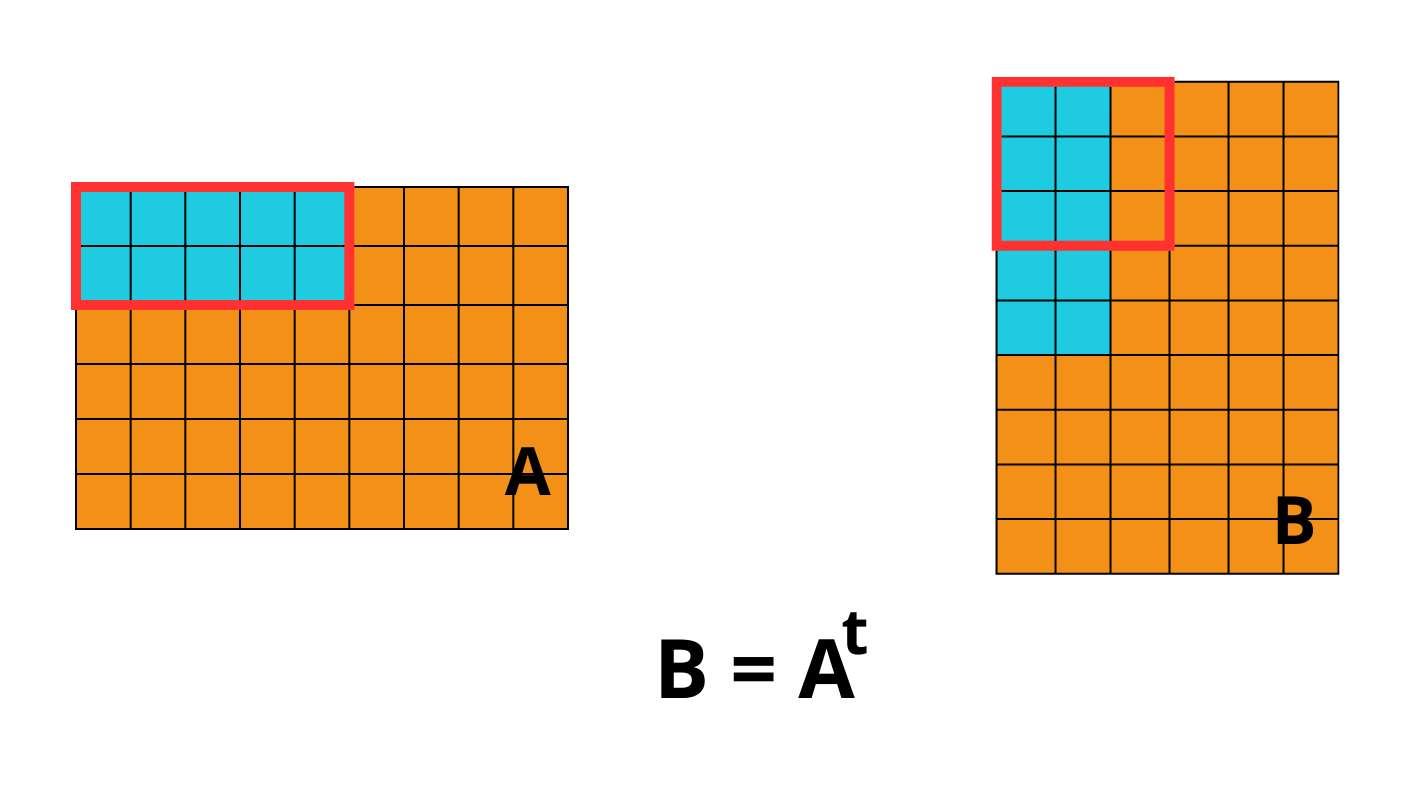
What was the old behavior?
Previously, calling blosc2.transpose(A) would transpose the data within
each chunk, and a new chunk shape would be chosen for the output array.
However, this new chunk shape was not necessarily aligned with the new memory
access patterns induced by the transpose. As a result, even though the output
looked correct, accessing data along the new axes still incurred a
significant overhead due to increased number of I/O operations. This
lead to performance bottlenecks, particularly in workloads that rely on
efficient memory access patterns.
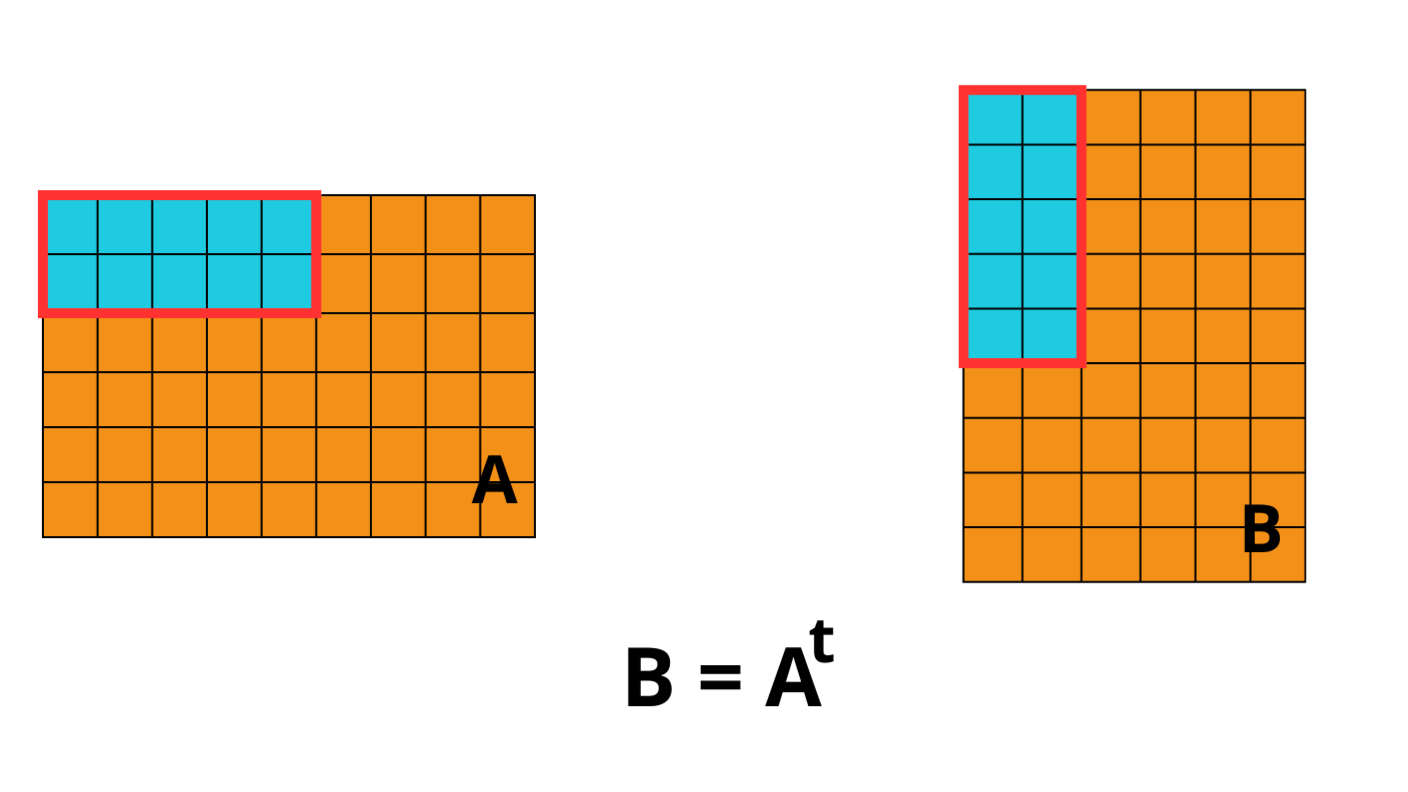
What's new?
The permute_dims function in Blosc2 has been redesigned to greatly improve
performance when working with compressed, multidimensional arrays. The main
improvement lies in transposing the chunk layout alongside the array data,
which eliminates the overhead of cross-chunk access patterns.
The new implementation transposes the chunk layout along with the data.
For example, an array with chunks=(2, 5) that is transposed with
axes=(1, 0) will result in an array with chunks=(5, 2). This ensures
that the output layout matches the new data order, making block access
contiguous and efficient.
This logic generalizes to N-dimensional arrays and applies regardless of their shape or chunk configuration.
Performance benchmark: Transposing matrices with Blosc2 vs NumPy
To evaluate the performance of the new matrix transposition implementation in Blosc2, I conducted a series of benchmarks comparing it to NumPy, which serves as the baseline due to its widespread use and high optimization level. The goal was to observe how both approaches perform when handling matrices of increasing size and to understand the impact of different chunk configurations in Blosc2.
Benchmark setup
All tests were conducted using matrices filled with float64 values,
covering a wide range of sizes, starting from small 100×100 matrices and
scaling up to very large matrices of size 17000×17000, covering data sizes
from just a few megabytes to over 2 GB. Each matrix was transposed using the
Blosc2 API under different chunking strategies:
In the case of NumPy, I used the .transpose() function followed by a
.copy() to ensure that the operation was comparable to that of Blosc2. This
is because, by default, NumPy's transposition is a view operation that only
modifies the array's metadata, without actually rearranging the data in memory.
Adding .copy() forces NumPy to perform a real memory reordering, making the
comparison with Blosc2 fair and accurate.
For Blosc2, I tested the transposition function across several chunk configurations. Specifically, I included:
Automatic chunking, where Blosc2 decides the optimal chunk size internally.
Fixed chunk sizes:
(150, 300),(1000, 1000)and(5000, 5000).
These chunk sizes were chosen to represent a mix of square and rectangular blocks, allowing me to study how chunk geometry impacts performance, especially for very large matrices.
Each combination of library and configuration was tested across all matrix sizes, and the time taken to perform the transposition was recorded in seconds. This comprehensive setup makes it possible to compare not just raw performance, but also how well each method scales with data size and structure.
Results and discussion
The chart below summarizes the benchmark results for matrix transposition using NumPy and Blosc2, across various chunk shapes and matrix sizes.
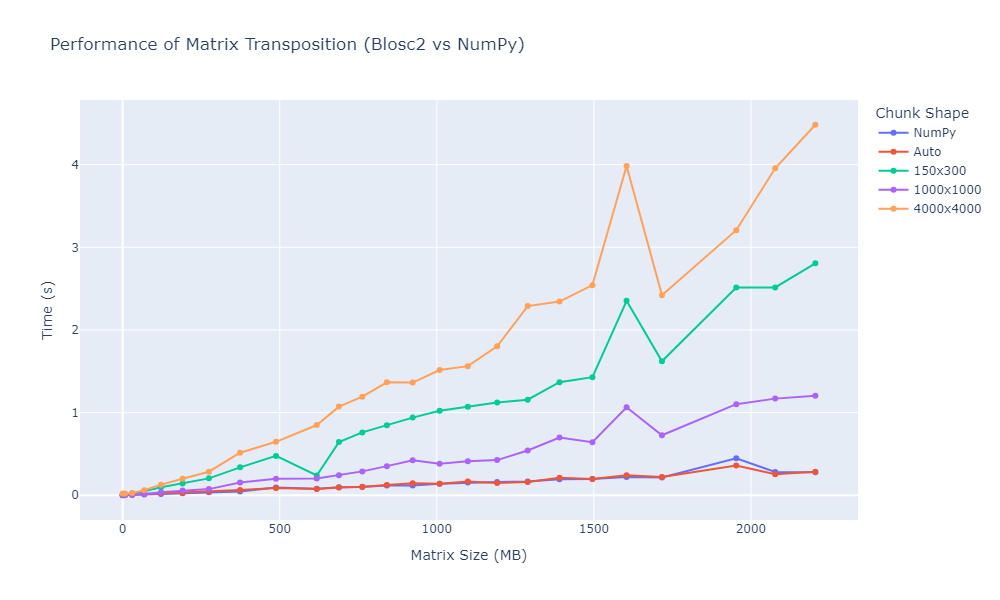
While NumPy sets a strong performance baseline, the behaviour of Blosc2 becomes particularly interesting when we dive into how different chunk configurations affect transposition speed. The following observations highlight how crucial the choice of chunk shape is to achieving optimal performance.
Large square chunks (e.g.,
(4000, 4000)) showed the worst performance, especially with large matrices. Despite having fewer chunks, their size seems to hinder cache performance and introduces memory pressure that degrades throughput. Execution times were consistently higher than other configurations.Small rectangular chunks such as
(150, 300)also underperformed. As matrix size grew, execution times increased significantly, reaching nearly 3 seconds at around 2200 MB, likely due to poor cache utilization and the overhead of managing many tiny chunks.Mid-sized square chunks like (1000, 1000) delivered consistently solid results across all tested sizes. Their timings stay below ~1.2 s with minimal variance, making them a reliable manual choice.
Automatically selected chunks consistently achieved the best performance. By adapting chunk layout to the data shape and size, the internal heuristics outpaced all fixed configurations, even rivaling plain NumPy transpose times.
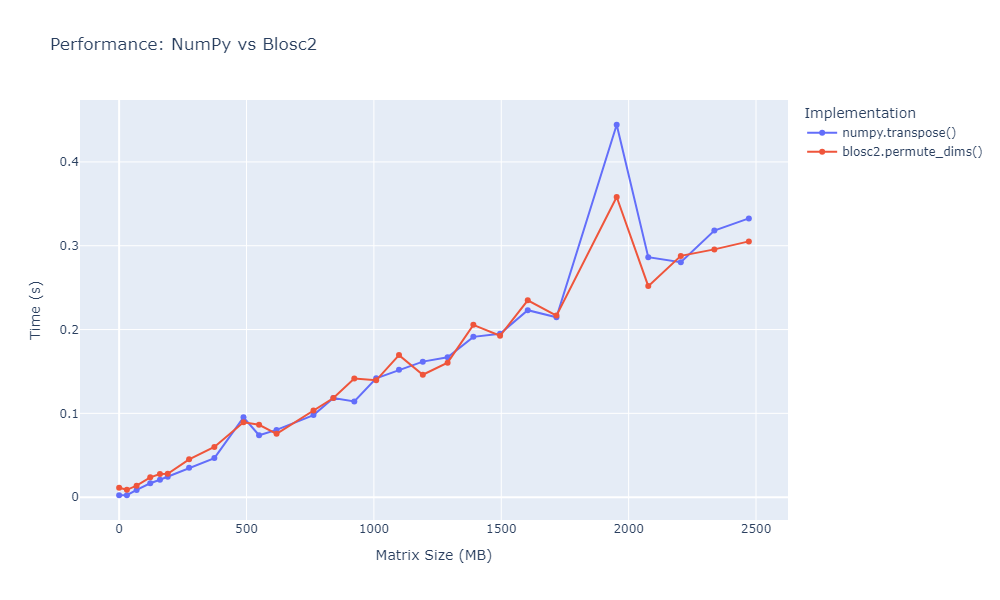
The second plot provides a direct comparison between the standard NumPy
transpose and the newly optimized Blosc2
version. It shows that Blosc2’s optimized implementation closely matches
NumPy's performance, even for larger matrices. The results confirm that with
good chunking strategies and proper memory handling, Blosc2 can achieve
performance on par with NumPy for transposition operations.
Conclusion
The benchmarks highlight one key insight: Blosc2 is highly sensitive to chunk shape, and its performance can range from excellent to poor depending on how it is configured. With the right chunk size, Blosc2 can offer both high-speed transpositions and advanced features like compression and out-of-core processing. However, misconfigured chunks, especially those that are too big or too small, can drastically reduce its effectiveness. This makes chunk tuning an essential step for anyone seeking to get the most out of Blosc2 for large-scale matrix operations.
Appendix A: Unexpected NumPy behaviour
While running the benchmarks, two unusual spikes were consistently observed in the performance of NumPy around matrices of approximately 500 MB, 1100 MB and 2000 MB in size. This can be clearly seen in the plot below:
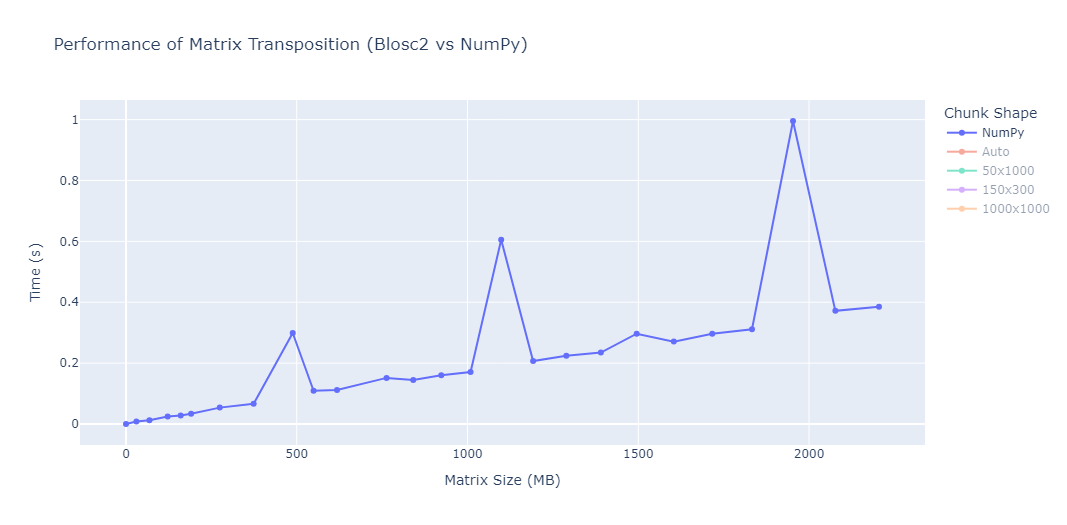
This sudden increase in transposition time is consistently reproducible and does not seem to correlate with the gradual increase expected from larger memory sizes. We have also observed this behaviour in other machines, although at different sizes.
This observation reinforces the importance of testing under realistic and varied conditions, as performance is not always linear or intuitive.
Comments
Comments powered by Disqus