Efficient array concatenation launched in Blosc2
Update (2025-06-23): Recently, Luke Shaw added a stack() function in Blosc2, using the concatenate feature described here. The new function allows you to stack arrays along a new axis, which is particularly useful for creating higher-dimensional arrays from lower-dimensional ones. We have added a section at the end of this post to show the usage and performance of this new function.
---
Blosc2 just got a cool new trick: super-efficient array concatenation! If you've ever needed to combine several arrays into one, especially when dealing with lots of data, this new feature is for you. It's built to be fast and use as little memory as possible. This is especially true if your array sizes line up nicely with Blosc2's internal "chunks" (think of these as the building blocks of your compressed data). When this alignment happens, concatenation is lightning-fast, making it perfect for demanding tasks.
You can use this new concatenate feature whether you're coding in C or Python, and it works with any Blosc2 NDArray (Blosc2's way of handling multi-dimensional arrays).
Let's see how easy it is to use in Python. If you're familiar with NumPy, the blosc2.concatenate function will feel very similar:
import blosc2 # Create some sample arrays a = blosc2.full((10, 20), 1, urlpath="arrayA.b2nd", mode="w") b = blosc2.full((10, 20), 2, urlpath="arrayB.b2nd", mode="w") c = blosc2.full((10, 20), 3, urlpath="arrayC.b2nd", mode="w") # Concatenate the arrays along the first axis result = blosc2.concat([a, b, c], axis=0, urlpath="destination.b2nd", mode="w") # The result is a new Blosc2 NDArray containing the concatenated data print(result.shape) # Output: (30, 20) # You can also concatenate along other axes result_axis1 = blosc2.concat([a, b, c], axis=1, urlpath="destination_axis1.b2nd", mode="w") print(result_axis1.shape) # Output: (10, 60)
The blosc2.concatenate function is pretty straightforward. You give it a list of the arrays you want to join together. You can also tell it which way to join them using the axis parameter (like joining them end-to-end or side-by-side).
A really handy feature is that you can use urlpath and mode to save the combined array directly to a file. This is great when you're working with huge datasets because you don't have to load everything into memory at once. What you get back is a brand new, persistent Blosc2 NDArray with all your data combined.
Aligned versus Non-Aligned Concatenation
Blosc2's concatenate function is smart. It processes your data in small pieces of compressed data (chunks). This has two consequences. The first is that you can join very large arrays, stored on your disk, chunk-by-chunk without using up all your computer's memory. Secondly, if the chunks fit neatly into the arrays to be concatenated, the process is much faster. Why? Because Blosc2 can avoid a lot of extra work, chiefly decompressing and re-compressing the chunks.
Let's look at some pictures to see what "aligned" and "unaligned" concatenation means. "Aligned" means that chunk boundaries of the arrays to be concatenated line up with each other. "Unaligned" means that this is not the case.
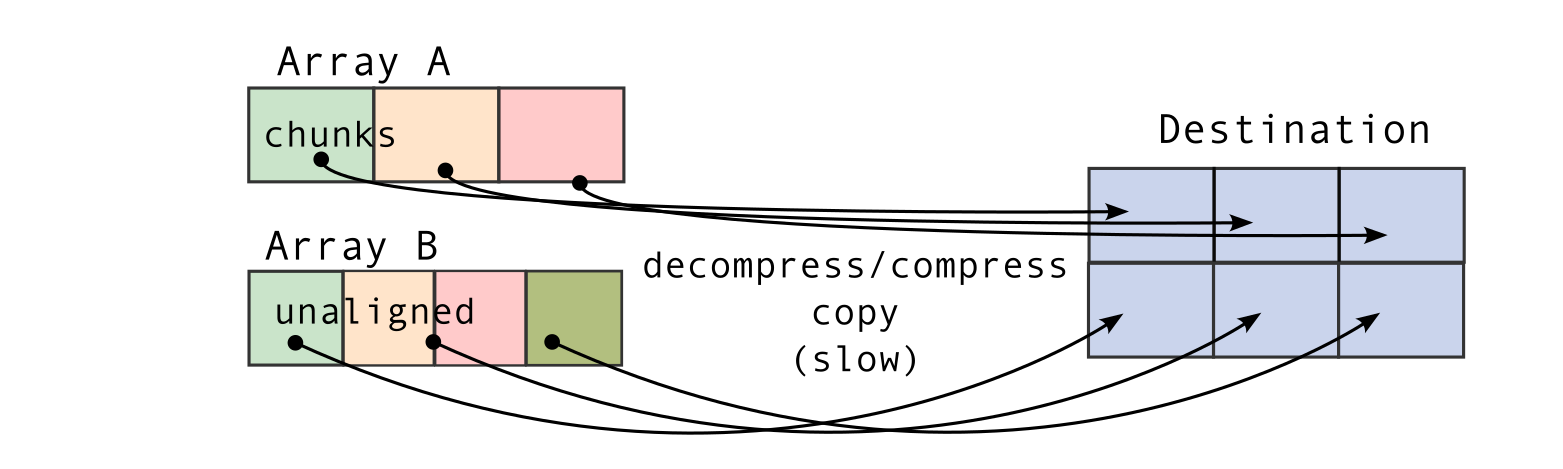
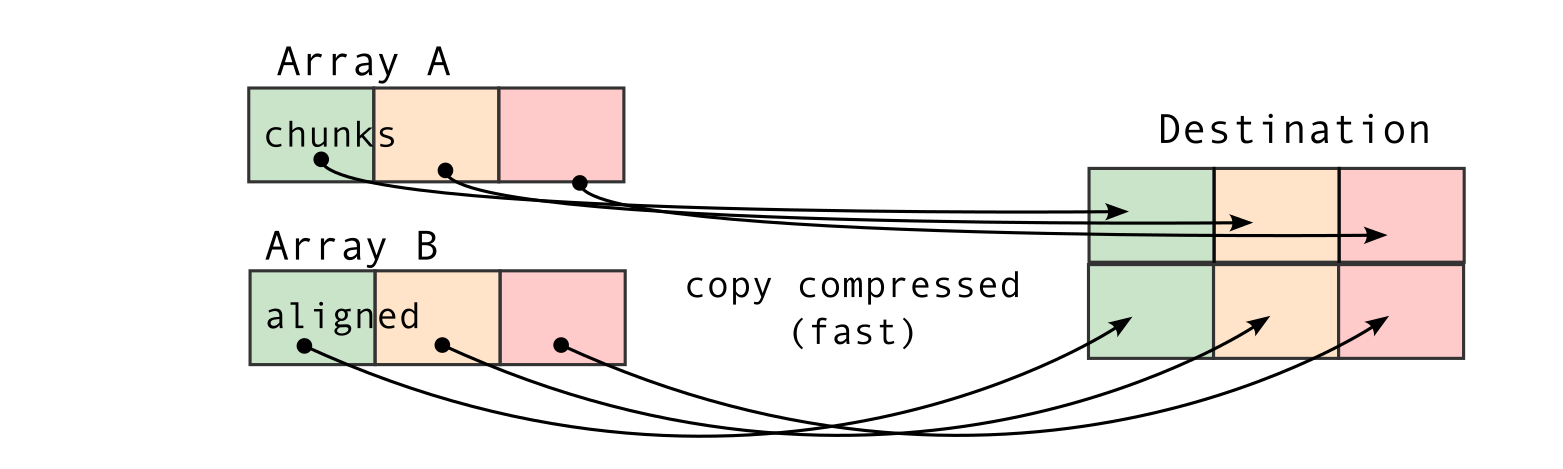
The pictures show why "aligned" concatenation is faster. In Blosc2, all data pieces (chunks) inside an array must be the same size. So, if the chunks in the arrays you're joining match up ("aligned"), Blosc2 can combine them very quickly. It doesn't have to rearrange the data into new, same-sized chunks for the final array. This is a big deal for large arrays.
If the arrays are "unaligned," Blosc2 has more work to do. It has to decompress and then re-compress the data to make the new chunks fit, which takes longer. There's one more small detail for this fast method to work: the first array's size needs to be a neat multiple of its chunk size along the direction you're joining.
A big plus with Blosc2 is that it always processes data in these small chunks. This means it can combine enormous arrays without ever needing to load everything into your computer's memory at once.
Performance
To show you how much faster this new concatenate feature is, we did a speed test using LZ4 as the internal compressor in Blosc2. We compared it to the usual way of joining arrays with numpy.concatenate.
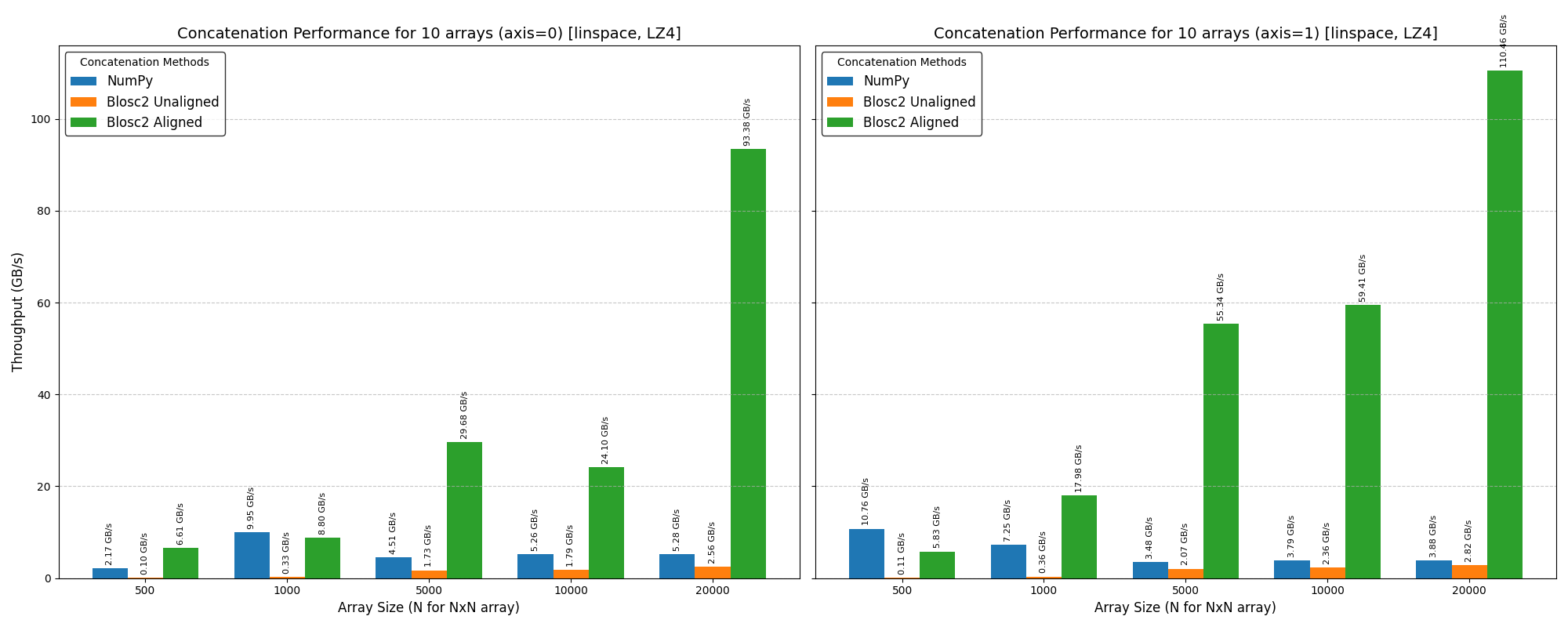
The speed tests show that Blosc2's new concatenate is rather slow for small arrays (like 1,000 x 1,000). This is because it has to do a lot of work to set up the concatenation. But when you use larger arrays (like 20,000 x 20,000) that start to exceed the memory limits of our test machine (32 GB of RAM), Blosc2's new concatenate peformance is much better, and nearing the performance of NumPy's concatenate function.
However, if your array sizes line up well with Blosc2's internal chunks ("aligned" arrays), Blosc2 becomes much faster—typically more than 10x times faster than NumPy for large arrays. This is because it can skip a lot of the work of decompressing and re-compressing data, and the cost of copying compressed data is also lower (as much as the achieved compression ratio, which for this case is around 10x).
Using the Zstd compressor with Blosc2 can make joining "aligned" arrays even quicker, since Zstd is good at making data smaller.
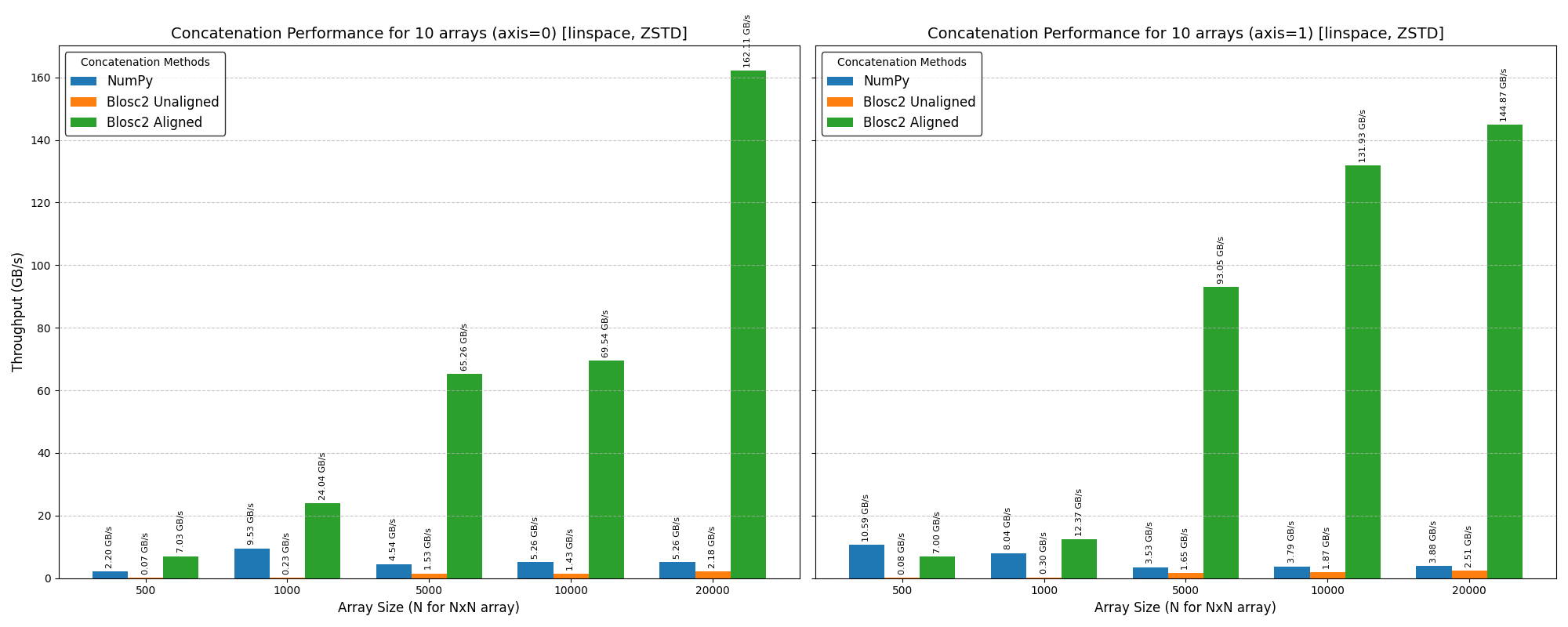
So, when arrays are aligned, there's less data to copy (compression ratios here are around 20x), which speeds things up. If arrays aren't aligned, Zstd is a bit slower than the previous compressor (LZ4) because its decompression and re-compression algorithm is slower. Conclusion? Pick the compressor that works best for what you're doing!
Stacking Arrays
We've also added a new stack() function in Blosc2 that uses the concatenate feature. This function lets you stack arrays along a new axis, which is super useful for creating higher-dimensional arrays from lower-dimensional ones. Here's how it works:
import blosc2 # Create some sample arrays a = blosc2.full((10, 20), 1, urlpath="arrayA.b2nd", mode="w") b = blosc2.full((10, 20), 2, urlpath="arrayB.b2nd", mode="w") c = blosc2.full((10, 20), 3, urlpath="arrayC.b2nd", mode="w") # Stack the arrays along a new axis stacked_result = blosc2.stack([a, b, c], axis=0, urlpath="stacked_destination.b2nd", mode="w") print(stacked_result.shape) # Output: (3, 10, 20) # You can also stack along other axes stacked_result_axis1 = blosc2.stack([a, b, c], axis=1, urlpath="stacked_destination_axis1.b2nd", mode="w") print(stacked_result_axis1.shape) # Output: (10, 3, 20)
Benchmarks for the stack() function show that it performs similarly to the concat() function, especially when the input arrays are aligned. Here are the results for the same data sizes and machine used in the previous benchmarks, and using the LZ4 compressor.
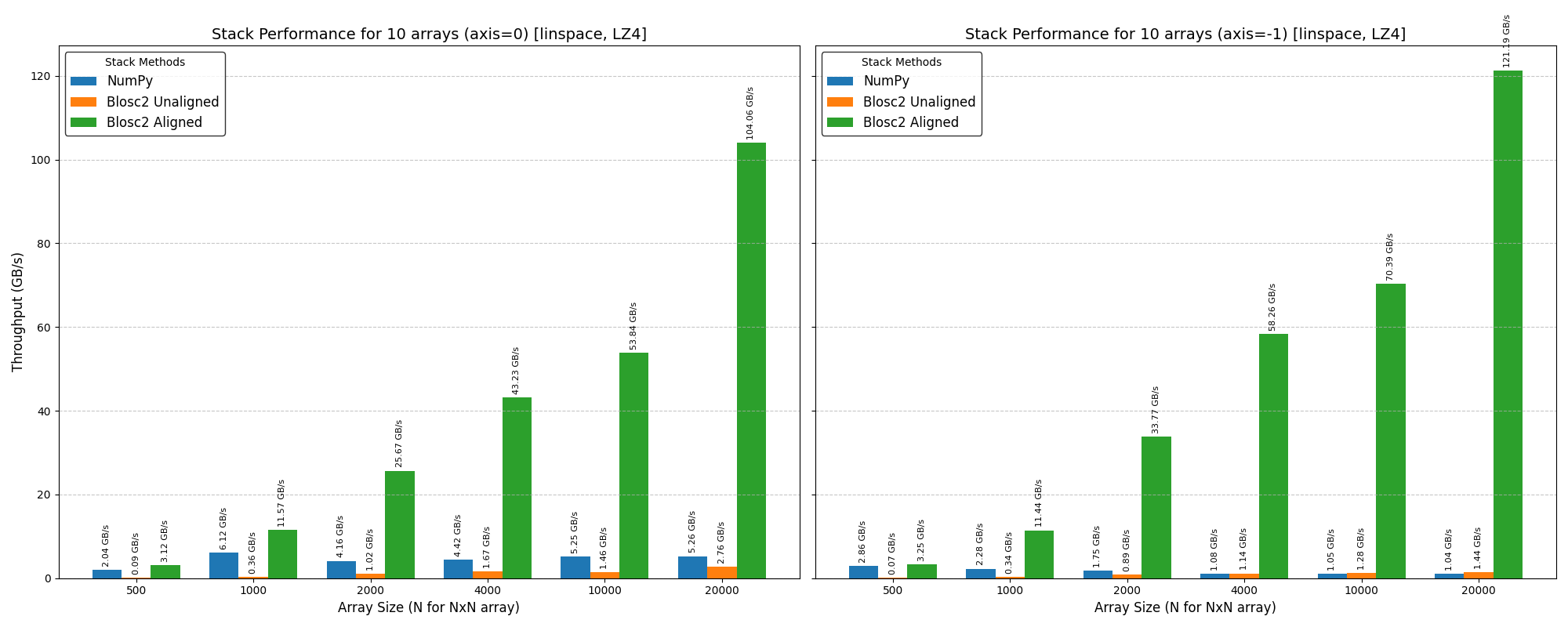
And here are the results for the Zstd compressor.
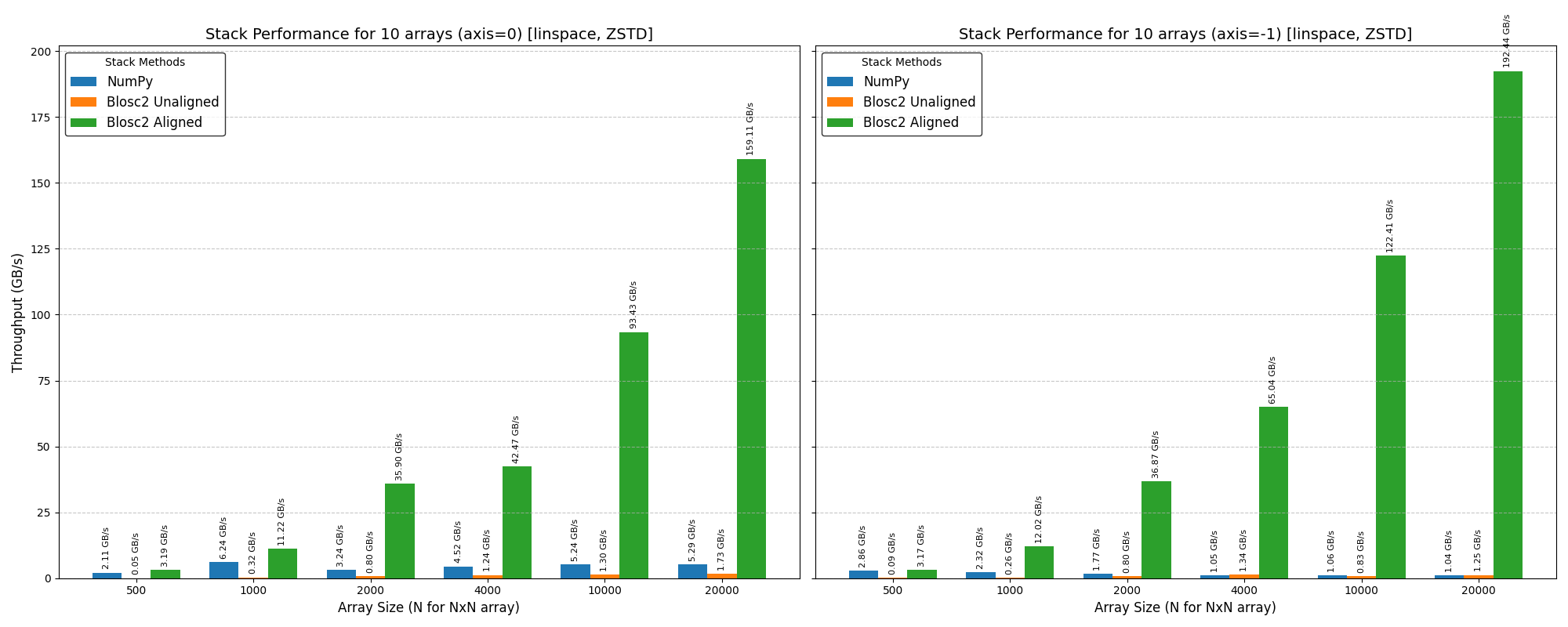
As can be seen, the stack() function is also very fast when the input arrays are aligned, and it performs well even for large arrays that don't fit into memory. Incidentally, when using the blosc2.stack() function in the last dim, it is slightly faster than numpy.stack() even when the arrays are not aligned; we are not sure why this is the case, but the fact that we can reproduces this behaviour is probably a sign that NumPy can optimize this use case better.
Conclusion
Blosc2's new concatenate and stack features are a great way to combine arrays quickly and without using too much memory. They are especially fast when your array sizes are an exact multiple of Blosc2's "chunks" (aligned arrays), making it perfect for big data jobs. They also work well for large arrays that don't fit into memory, as it processes data in small chunks. Finally, they are supported in both C and Python, so you can use them in your favorite programming language.
Give it a try in your own projects! If you have questions, the Blosc2 community is here to help.
If you appreciate what we're doing with Blosc2, please think about supporting us. Your help lets us keep making these tools better.
Comments
Comments powered by Disqus